The first time I heard about this thing called “the Singularity” was when I read Ray Kurzweil’s 2005 book The Singularity is Near. Prior to this, I’d been the kind of person who spent most of their free time thinking about things like politics and social issues, because I was convinced that those were the most important and consequential things a person could spend their time thinking about. After reading Kurzweil’s book, though, it immediately became apparent to me – and has become increasingly apparent ever since – that although things like politics are definitely very important, they aren’t actually the most important thing in the world right now. The most important thing in the world right now – the thing that, if and when it happens, will be the most important thing that has ever happened in the history of our species – is the thing Kurzweil was talking about: the Singularity.
So what is the Singularity? There’s a pretty good chance at this point that you’re already familiar with the concept, but if not, the basic idea is that our technology – which has always developed at a pretty steady and predictable pace throughout history – is about to reach a critical turning point, after which our level of advancement will suddenly skyrocket and give us centuries’ worth of technological progress in a matter of a few short years or months – or, if it goes wrong, could completely wipe out all life on Earth. This is a pretty dramatic claim, to put it mildly. But if it’s right – and I think it is – it’s something that we not only should be taking seriously, but should be directing practically all our focus toward as a society – because it’s the thing that will make or break our entire species; and we’re approaching it very, very quickly.
But I’m getting ahead of myself here; let’s back up for a minute. Whenever there’s any kind of abstract talk about the future like this, people’s minds tend to automatically go in a certain direction. Most people, when they imagine “the future,” envision something like The Jetsons or Blade Runner or Wall-E, where technology has basically continued to evolve in the same kind of way that it has in the past (and at roughly the same rate), until eventually – over the course of the next century or two – we’ve developed things like hovercars and robot butlers and holograms and so on, and our society has transformed into one that’s largely still recognizable as the same kind of human society we have today, just with niftier gadgets. What most people don’t envision is a kind of future that we’d find totally unrecognizable today – like one in which, say, humans have become immortal demigods who can reshape matter at will, or one in which the entire human species has transformed itself into a multi-star-system-spanning swarm of microscopic nanomachines sharing a universal cloud consciousness that everyone has uploaded their minds into – nor do they imagine that such an outcome could be even remotely conceivable within any kind of time frame that could be described as “the near future.” Certainly they’d find the idea of it occurring within their own lifetimes to be absolutely absurd. But what the idea of the Singularity suggests is that, as crazy as it might sound, these assumptions might actually be wrong.
See, what the popular conception of the future assumes is that technological advancement generally follows a linear progression; that is to say, it takes for granted that the rate of progress in any given decade or century will be roughly the same as in the one that came before. As Tim Urban puts it:
When it comes to history, we think in straight lines. When we imagine the progress of the next 30 years, we look back to the progress of the previous 30 as an indicator of how much will likely happen. When we think about the extent to which the world will change in the 21st century, we just take the 20th century progress and add it to the year 2000.
But as Kurzweil points out, this isn’t actually how technological advancement works, and never has been. Technological progress isn’t additive – increasing by the same fixed amount every century – it’s multiplicative. Each century takes the advancements of the previous ones and uses those advancements to advance even more quickly still – with the result being that each successive century isn’t just more advanced than the previous one; it advances by an even greater amount every time. The kind of technology we have today is many times more advanced than what they had in 1950, which was many times more advanced than what they had in 1850, which was many times more advanced than in 1750, and so on – with the differences growing greater and greater in absolute terms with each passing century. Here’s Urban again:
This pattern—human progress moving quicker and quicker as time goes on—is what futurist Ray Kurzweil calls human history’s Law of Accelerating Returns. This happens because more advanced societies have the ability to progress at a faster rate than less advanced societies—because they’re more advanced. 19th century humanity knew more and had better technology than 15th century humanity, so it’s no surprise that humanity made far more advances in the 19th century than in the 15th century—15th century humanity was no match for 19th century humanity.
This works on smaller scales too. The movie Back to the Future came out in 1985, and “the past” took place in 1955. In the movie, when Michael J. Fox went back to 1955, he was caught off-guard by the newness of TVs, the prices of soda, the lack of love for shrill electric guitar, and the variation in slang. It was a different world, yes—but if the movie were made today and the past took place in 1985, the movie could have had much more fun with much bigger differences. The character would be in a time before personal computers, internet, or cell phones—today’s Marty McFly, a teenager born in the late 90s, would be much more out of place in 1985 than the movie’s Marty McFly was in 1955.
This is for the same reason we just discussed—the Law of Accelerating Returns. The average rate of advancement between 1985 and 2015 was higher than the rate between 1955 and 1985—because the former was a more advanced world—so much more change happened in the most recent 30 years than in the prior 30.
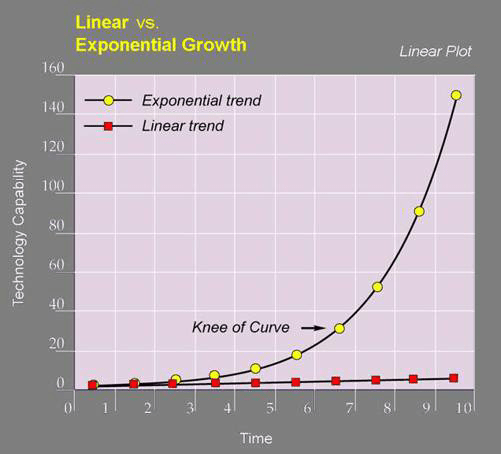
In short, our technological capabilities aren’t just growing; the rate at which they’re growing is itself growing. Technological progress is accelerating, not in a linear progression, but in an exponential one. This is how it has always worked, and it’s how it continues to work today.
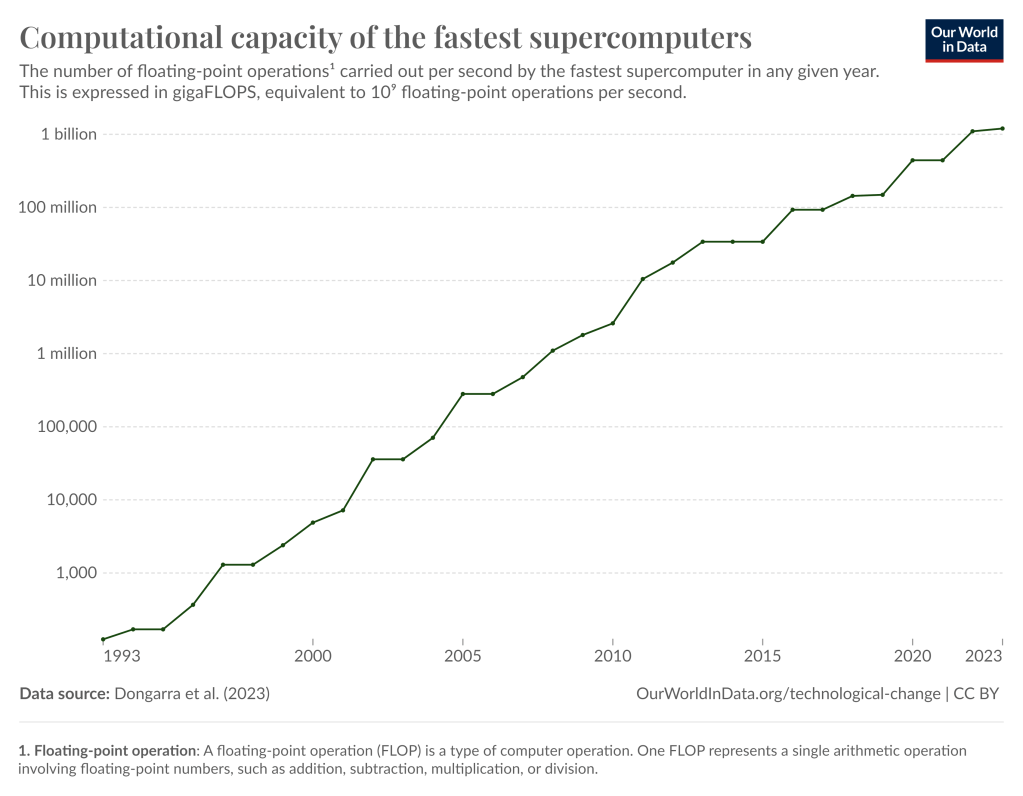
Probably the most famous example of this phenomenon in modern-day technologies is Moore’s Law, which observes that the capability level of computer chips (as measured by their transistor count) has roughly doubled every two years, and has been doing so for the last 50 years and counting:
Note that the y-axis in this chart is on a logarithmic scale (i.e. increasing by multiples) rather than a linear scale (i.e. increasing by fixed increments), just to make it easier to see how clear the trend line is. Converting this to a normal linear scale, though – to provide a more intuitive picture of how clearly progress is accelerating over time – it looks like this:
And it’s not just transistor counts where we see this trend, either; it shows up everywhere, from computational speed…
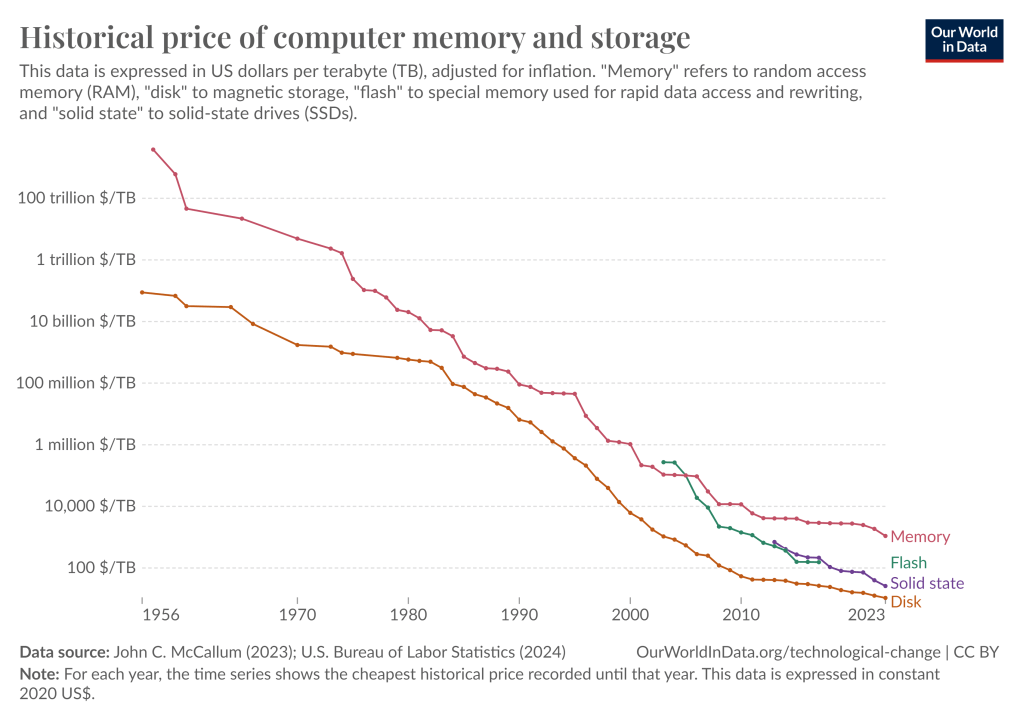
…to the efficiency and cost of memory and storage:
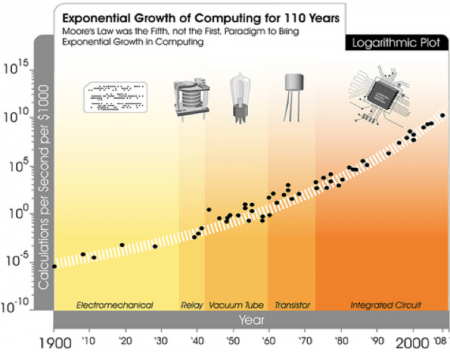
Even if we extend the time frame all the way back to before modern computers even existed, back when computations were still done with punch cards and vacuum tubes, the trend still holds true:
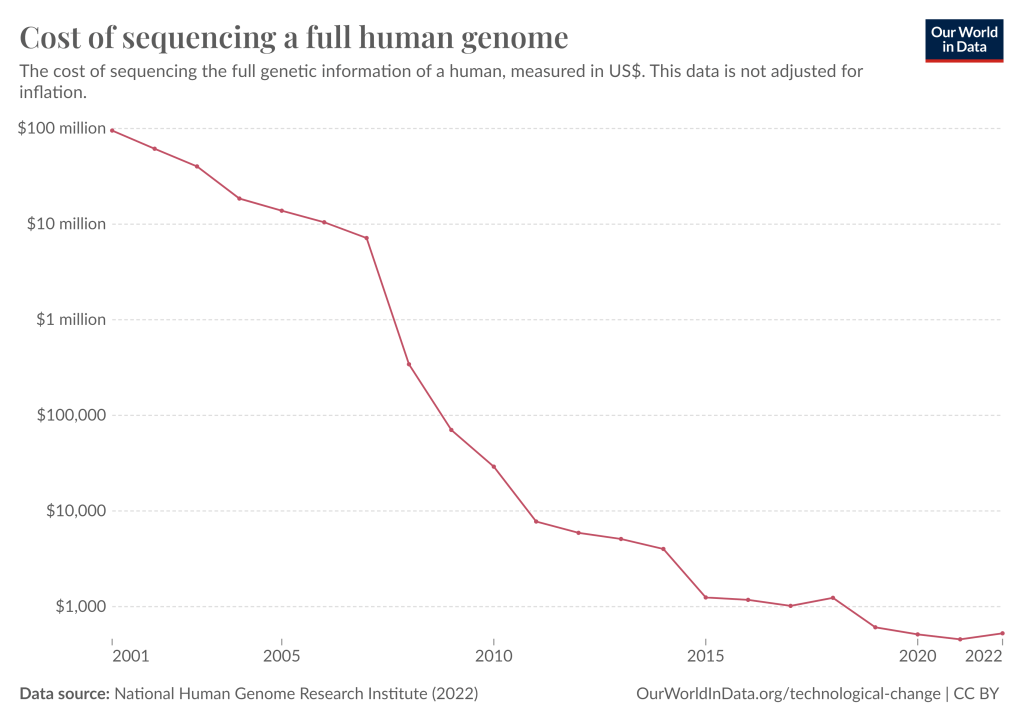
Nor is it only computer technology that follows this trend; the same pattern can be seen in all kinds of different areas of technological development. Here’s a chart showing how much the efficiency of genome sequencing has improved over time, for instance:
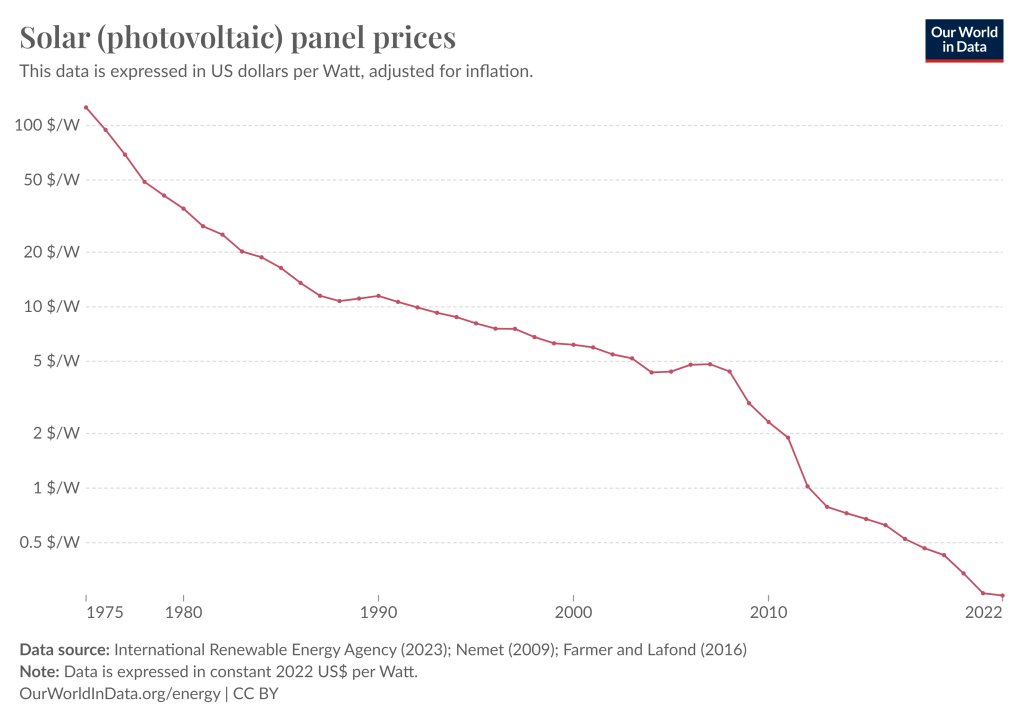
And here’s one for solar panels:
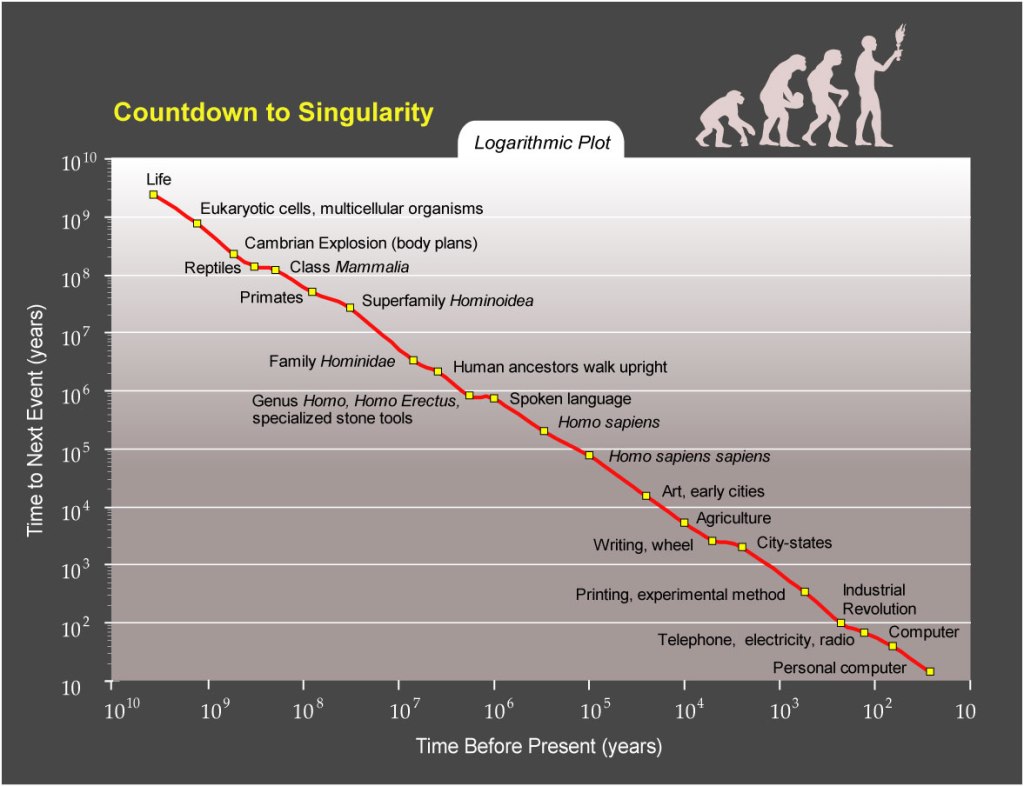
The list of examples goes on. Kurzweil provides dozens more such charts in his book, covering everything from phones to internet data to mechanical devices, and shows them all following the same pattern. In fact, he considers the Law of Accelerating Returns to be so ubiquitous that he even goes so far as to apply it to the entire history of our species:
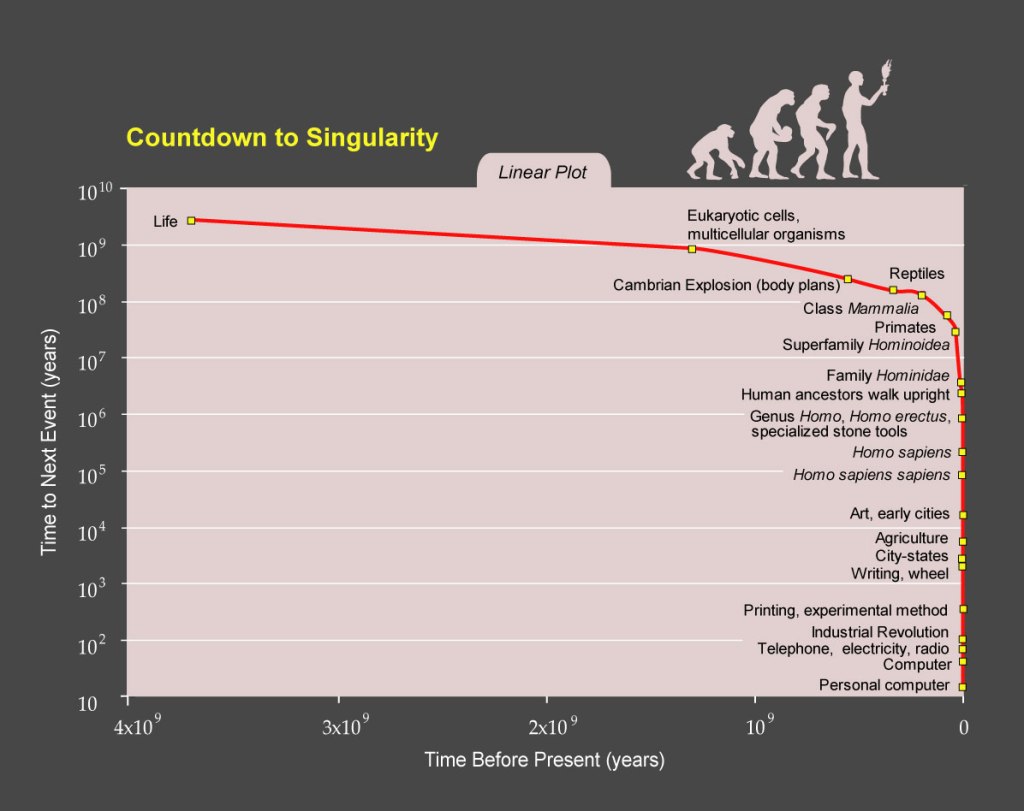
And again, just to see how accelerative this whole process has been, here’s the same chart on a linear scale:
In all of these cases, we can see that progress follows a pattern of exponential growth, not linear growth. Things seem to be moving slowly and steadily for a while, but then at some point the pace suddenly starts to pick up, and before you can even fully realize what’s going on, the trajectory skyrockets. To borrow a line from John Green (who himself was paraphrasing Ernest Hemingway), it’s like falling asleep – it happens slowly at first, then all at once. And because this kind of accelerative exponential growth is naturally so unintuitive to our primate brains, which are so much more accustomed to everything in daily life following a more linear trend, it can completely catch us off guard when it does happen. As Kurzweil writes:
The pace of change of our human-created technology is accelerating and its powers are expanding at an exponential pace. Exponential growth is deceptive. It starts out almost imperceptibly and then explodes with unexpected fury—unexpected, that is, if one does not take care to follow its trajectory.
[…]
Consider Gary Kasparov, who scorned the pathetic state of computer chess in 1992. Yet the relentless doubling of computer power every year enabled a computer to defeat him only five years later.
Or for another famous example, consider the New York Times editorial published in October of 1903, which predicted that it would take one to ten million years to develop a functioning flying machine. This seemed like a perfectly reasonable prediction at the time – after all, it was only a few years earlier that Lord Kelvin (among many others) had proclaimed that heavier-than-air flying machines would simply never be possible at all – but just two months after the prediction was made, Orville and Wilbur Wright succeeded in building the world’s first working airplane. And a mere 65 years after that – less than a single lifetime – humans were walking on the moon.
In the early years of the twentieth century, perhaps no nuclear physicist was more distinguished than Ernest Rutherford, the discoverer of the proton and the “man who split the atom.” Like his colleagues, Rutherford had long been aware that atomic nuclei stored immense amounts of energy; yet the prevailing view was that tapping this source of energy was impossible.
On September 11, 1933, the British Association for the Advancement of Science held its annual meeting in Leicester. Lord Rutherford addressed the evening session. As he had done several times before, he poured cold water on the prospects for atomic energy: “Anyone who looks for a source of power in the transformation of the atoms is talking moonshine.” Rutherford’s speech was reported in the Times of London the next morning.
Leo Szilard, a Hungarian physicist who had recently fled from Nazi Germany, was staying at the Imperial Hotel on Russell Square in London. He read the Times’ report at breakfast. Mulling over what he had read, he went for a walk and invented the neutron-induced nuclear chain reaction. The problem of liberating nuclear energy went from impossible to essentially solved in less than twenty-four hours. Szilard filed a secret patent for a nuclear reactor the following year. The first patent for a nuclear weapon was issued in France in 1939.
There are all kinds of examples like this, where very reasonable people make very reasonable predictions that some new technology will perhaps emerge in a thousand or two thousand years if we’re lucky, based on past trends – only for it to be invented within their lifetime, or sometimes even within that same year. But their mistake, of course, is precisely to base their predictions on past trends, because the trend itself is the very thing that’s accelerating. As Urban puts it:
It’s most intuitive for us to think linearly, when we should be thinking exponentially. If someone is being more clever about it, they might predict the advances of the next 30 years not by looking at the previous 30 years, but by taking the current rate of progress and judging based on that. They’d be more accurate, but still way off. In order to think about the future correctly, you need to imagine things moving at a much faster rate than they’re moving now.
Just to drive this point home, here’s one more analogy, adapted from Shakuntala Devi. Imagine, she says, a big lake with a tiny patch of lily pads in one corner of it. Every day the patch of lily pads doubles in size, until after exactly one year it has grown so much that it now covers the entire lake. At what point would the lake have been half covered in lily pads? Our intuitive response, naturally, will be to say that if it took one year to cover the whole lake, then it must have taken half that time – six months – to cover half of it. But this answer is wrong. Since the patch of lily pads is doubling in size every day, that means that it would have been covering half the lake on day 364 – just one day before it was covering the whole lake – and the day before that, on day 363, it would have been covering one-fourth of the lake, and the day before that, on day 362, it would have been covering one-eighth of the lake, and so on. If you’d been watching from the very beginning, you wouldn’t have noticed the patch get large enough to cover even 1% of the lake until the very last week of the year; your first 11.8 months would have been completely uneventful, but then in that last week, the growth would have suddenly seemed to explode out of nowhere. It would have gone from <1% coverage to 100% coverage in just those last seven doublings. Again, though, that’s how it goes with exponential growth; it feels similar to linear growth at first, but then all of a sudden it doesn’t. Slowly, then all at once.
So what specifically does this mean for us and our immediate future? Looking back over all these charts, it’s hard not to notice that (depicted on a linear scale) they all seem to be approaching a point of maximal acceleration – a point at which that upward-curving exponential trend line will become nearly vertical. As Kurzweil writes:
In the 1950s John von Neumann, the legendary information theorist, was quoted as saying that “the ever-accelerating progress of technology … gives the appearance of approaching some essential singularity in the history of the race beyond which human affairs, as we know them, could not continue.” Von Neumann makes two important observations here: acceleration and singularity.
The first idea is that human progress is exponential (that is, it expands by repeatedly multiplying by a constant) rather than linear (that is, expanding by repeatedly adding a constant).
The second is that exponential growth is seductive, starting out slowly and virtually unnoticeably, but beyond the knee of the curve it turns explosive and profoundly transformative. The future is widely misunderstood. Our forebears expected it to be pretty much like their present, which had been pretty much like their past. Exponential trends did exist one thousand years ago, but they were at that very early stage in which they were so flat and so slow that they looked like no trend at all. As a result, observers’ expectation of an unchanged future was fulfilled. Today, we anticipate continuous technological progress and the social repercussions that follow. But the future will be far more surprising than most people realize, because few observers have truly internalized the implications of the fact that the rate of change itself is accelerating.
Right now, by Kurzweil’s reckoning, we’re right at the knee of the curve. We’re leaving the “slowly at first” stage and are about to enter the “all at once” stage. So again, what does this mean? According to Kurzweil, it means that the 21st century won’t just achieve more technological progress than the 20th century – it’ll achieve thousands of times more.
But wait a minute – how can that even be possible? Sure, things like Moore’s Law might be fine for describing how technology has evolved up to this point, but just because a pattern has held true in the past doesn’t mean that we can just extrapolate it forward into the future indefinitely; at some point it will have to level off, just due to the laws of physics, right? And yes, of course that’s true, particularly when it comes to specific paradigms like Moore’s Law. Moore’s Law is all about how many transistors can fit on an integrated circuit – but eventually there will come a point where those transistors will have gotten down to the smallest possible molecular scale and won’t be able to get any smaller; that’s just a hard physical limit. Having said that, though, Moore’s Law is just one paradigm describing the evolution of one piece of technology; the fact that it will eventually level off doesn’t mean that all technological progress will therefore stop. There are all kinds of other ways to improve computing performance besides just making transistors smaller – so once we’ve reached the limits of Moore’s Law, the natural next step will be to simply shift technical resources into other areas where there’s still plenty of room left for progress, like expanding chip architecture (e.g. making 3D chips that stack transistors vertically), optimizing chip-specific task specialization, improving memory bandwidth, designing better software, developing other forms of computation that don’t even involve transistors at all, like optical computing or memristors, etc. (See Sarah Constantin’s explanation of all this here.) This is just the natural course of technological development, as Kurzweil explains; once one particular technological paradigm matures and begins to level off, it creates an opportunity for the next paradigm to emerge and start ramping up. Each new technology follows a kind of S-curve as it emerges, grows into its full potential, plateaus, and then gives rise to new successor technologies – and the result at the fine-grained level of individual technologies is a kind of punctuated equilibrium, with relatively quiet periods interspersed with sudden bursts of progress. But the combined result of all these S-curves – the broader trend of technological advancement as a whole – is still a consistent exponential curve upward.
So while it’s true that there must eventually be some kind of absolute upper limit on how far technology can advance, the idea that we’re anywhere near that ceiling right now just seems woefully short-sighted. Indeed, it would be an awfully strange coincidence if, after millennia of consistent exponential progress, it was only right now that progress just completely stopped. The whole nature of progress is to build upon itself; the more advanced technology we create, the more it enables us to use that very technology to create even more advanced technology still, in a self-reinforcing positive feedback loop. And in fact, the way things are going, it’s looking like these next few paradigms we’re on the verge of cracking open – artificial intelligence, brain-machine interfacing, etc. – will have an even more dramatically multiplicative impact than anything that has come before – because for the first time, they’ll give us the ability to multiply our own intelligence itself, and by extension our ability to unlock even more extraordinary technological breakthroughs than ever, at a more breakneck pace than ever. As impressive as our progress has been up to this point, it’s these upcoming technologies that are primed to give us a whole new understanding of what explosive exponential progress can really mean – whether we’re ready for it or not.
II.
But again, I’m getting ahead of myself; let’s back up one more time. The way Kurzweil explains it, the upcoming explosion of technological progress will actually feature three overlapping revolutions – three areas where its impact will be greatest – in biotechnology, nanotechnology, and AI. We can already see progress in these areas beginning to ramp up in some clear ways: With biotechnology, for instance, we’ve long had the ability to augment our bodies with machines to improve their functioning – e.g. with pacemakers and hearing aids and so on – but more recently we’ve expanded this to include implants in the brain as well, which can stop the effects of conditions like epilepsy, OCD, and Parkinson’s Disease, and are even being developed to treat depression and Alzheimer’s Disease. There have also been major recent breakthroughs in developing technologies to grow replacement organs from scratch in the lab, so that patients with failing organs can get new ones fabricated on demand without the need for organ donors. And even more dramatic leaps are being made in the area of genetic engineering, which can and will give us the power to reprogram our own biology at the most fundamental level; the first babies have already been born who’ve had their genomes edited to make them immune to certain diseases, and in time this will only become more commonplace. It won’t be long before everyone is customizing their babies’ genomes to not only give them immunity to diseases, but also things like enhanced metabolism, perfect eyesight, peak physique, heightened intelligence, and more. Kurzgesagt has a great video on the subject:
And this is only the tip of the iceberg. Just in the last few years, there have been decades’ worth of breakthroughs in biotechnology, as Sveta McShane points out:
Major innovations in biotech over the last decade include:
And in fact, just since that article was posted in 2016, we’ve had multiple breakthroughs which on their own would be considered once-in-a-lifetime advances. We’ve developed a brain implant that can help treat blindness. We’ve grown a mouse embryo from nothing but stem cells, without the use of sperm or eggs or a womb. We’ve discovered an effective cure for obesity – one which, unbelievably, also seems to work as a treatment for a whole array of other things, from diabetes to alcoholism to drug addiction to heart disease to kidney disease to stroke to Parkinson’s to Alzheimer’s to COVID-19. And speaking of COVID, our efforts against the COVID pandemic allowed us to unlock a whole new category of vaccines, mRNA vaccines, which could potentially lead to cures not only for COVID, but for a whole slew of other diseases which currently kill millions, including malaria, HIV, and even various types of cancer, as Noah Smith notes:
Vaccine technology just took a huge leap forward. Propelled by the crisis of COVID, mRNA vaccines went from a speculative tool to a proven one. This will probably accelerate the development of all kinds of new vaccines, potentially including vaccines for cancer. It’s worth reading that phrase again and thinking about it for a second: VACCINES FOR CANCER.
And again, all of this is just what’s happening right now; we haven’t even gotten into the breakthroughs that we’re on track to make in the near future. The way things are going (and assuming we don’t screw things up in the meantime somehow), it’ll only be a matter of time before we’re able to introduce respirocytes into our bloodstreams – tiny robotic blood cells that will enable us to run for 15 minutes at a dead sprint without getting winded, or sit at the bottom of a swimming pool for hours without taking a breath. We’ll have technologies that will allow us to recover from practically any injury (even the most debilitating ones), like salamanders re-growing lost limbs. We’ll even have the ability to counteract the cellular degeneration that causes our bodies to break down as we get older; that is, we’ll have the ability to reverse the aging process itself. I’ve posted this TED talk from Aubrey de Grey here before, but I think it’s worth posting again just because what he’s talking about here is so remarkable:
It’s hard to overstate the significance of all this. Being able to extend human lifespans indefinitely – to conquer death itself (or at least “natural death”) – would be by far the most momentous development in human history. (And we’ll come back to this point in a moment.) But even aside from matters of lifespan and mortality, the implications of all these technologies just in terms of everyday quality of life would be indescribable. If you’re someone who’s currently feeling despondent, for instance, because you feel like you missed your window to have kids and now you’re too old, well, you might soon be able to restore your body back to its youthful peak condition and have another chance (either via old-fashioned pregnancy or through the use of an artificial womb). Quadriplegic? Hang in there; you just might be able to get the full use of your body back in time. Suffering from any kind of chronic health condition at all? As wild as it sounds, it’s no exaggeration to say that given the continuing acceleration of progress in medicine and biotechnology, there might not be any kind of malady whatsoever that doesn’t have a legitimately good chance of becoming curable within our lifetimes.
But as big as the impact of these technologies would be on our ability to remedy our maladies and keep ourselves in perfect condition, the place where the implications would be biggest of all would be in enhancing not just our physical abilities, but our brainpower. I already briefly mentioned gene editing as one potential way of enhancing human intelligence, but we’re also likely to see increasingly rapid advancement of technologies designed to boost intelligence in even more direct ways, e.g. via chemical and/or pharmaceutical means (AKA nootropics). Even more potent still is the emerging technology of brain-machine interfacing – hooking up a person’s brain to a computer and thereby augmenting their own natural thinking abilities with all the additional capabilities of the computer. This technology has already come into use as a tool for enabling people with severe disabilities to do things they wouldn’t normally be able to do; for instance, here’s a sample of “handwriting” from a man who, despite being paralyzed from the neck down, was able to use a brain-computer interface to make the letters appear onscreen simply by thinking about writing them:
And this technology is only going to become more sophisticated in the next few years. As we become better and better at designing machines that can directly integrate with our brains, it will eventually progress to a point where we’re able to significantly enhance the speed, memory, and storage capacity of our brains using computer peripherals. In other words, we’ll gain the ability to upgrade our own brainpower. And when that happens, all bets are off when it comes to making even more dramatic subsequent leaps in advancement – because as Eliezer Yudkowsky points out, our level of intelligence is the pivotal factor determining our rate of scientific and technological progress:
The great breakthroughs of physics and engineering did not occur because a group of people plodded and plodded and plodded for generations until they found an explanation so complex, a string of ideas so long, that only time could invent it. Relativity and quantum physics and buckyballs and object-oriented programming all happened because someone put together a short, simple, elegant semantic structure in a way that nobody had ever thought of before. Being a little bit smarter is where revolutions come from. Not time. Not hard work. Although hard work and time were usually necessary, others had worked far harder and longer without result. The essence of revolution is raw smartness.
“Think about a chimpanzee trying to understand integral calculus,” he adds. No matter how persistent or well-resourced the chimp is, there’s simply no way it will ever be able to succeed. Give the chimp a bit of extra brainpower, though – enough to put it at the level of a fairly smart human – and all of a sudden the impossible task becomes perfectly feasible. And the same is true of us humans and our current levels of intelligence; boost it just a little, and we suddenly become capable of making breakthroughs that might previously have seemed impossible:
There are no hard problems, only problems that are hard to a certain level of intelligence. Move the smallest bit upwards, and some problems will suddenly move from “impossible” to “obvious”. Move a substantial degree upwards, and all of them will become obvious.
The development of technology for enhancing intelligence is the master key to our entire future – because as soon as we do develop such a technology, it will allow us to even more quickly develop more technologies for enhancing our intelligence further still, which will allow us to develop even more technologies for enhancing our intelligence further still, and so on in an exponentially accelerating positive feedback loop until we’ve reached seemingly impossible heights of advancement. The breakthroughs will just keep coming faster and faster until practically overnight our entire world is transformed. That’s what could potentially be in our very near future – or at least, that’s what it could look like if we go the biotechnology route. As it happens, though, biotechnology isn’t actually the only means by which we might unlock the capacity for self-improving intelligence. Another is the second of Kurzweil’s three overlapping revolutions – AI.
The term “AI” can refer to a few different things. At the most rudimentary level, it can just refer to things like GPS devices and chess-playing computers and digital assistants like Siri and Alexa, which are already so widespread that you’ve probably interacted with several of them yourself recently. These are what are called “narrow AIs,” because while they’re great for accomplishing certain very specific tasks (and can even outperform humans within those specialized sub-domains), they aren’t much use outside those narrow contexts, and so can’t rightly be considered “just as intelligent as a human” in the most general sense. When we’re talking about truly revolutionary AI, though, we aren’t just talking about these kinds of limited-use tools; what we’re talking about instead is AI that actually would be considered as intelligent as a human in the general sense – so-called “artificial general intelligence,” or AGI. As Urban describes it, this is AI “that is as smart as a human across the board—a machine that can perform any intellectual task that a human being can.”
So how could we create such an AI? Well, the first thing we’d need to do would be to simply make sure that we actually have hardware powerful enough to operate at a comparable level to the human brain. The brain is capable of running at a rate that, in computing terms, would be the equivalent of up to one quintillion operations per second – a level of performance that, for most of computing history, has been far out of reach. But as computing power has continued to advance at an accelerating rate, we’ve finally gotten to the point where we actually have just now crossed that critical threshold. We’re now building supercomputers that really can match the performance of the human brain. All that’s left for us to do at this point, then, is to figure out the software side of the equation – i.e. how to encode something as intelligent as a human brain in a digital format. And obviously, that’s not something that anyone would be able to do just by programming in every line of code from scratch; nobody understands the brain that well (at least not currently). So what we’ve done instead is come up with some shortcuts – strategies that would allow us to create an advanced digital intelligence even without fully understanding it first.
The most straightforward such strategy would be to simply plagiarize the brain wholesale – to develop brain-scanning technology of such high resolution that it would be able to map out an entire brain with perfect accuracy, down to the level of individual neurons and synapses, and then recreate that brain virtually. In this scenario, the newly-created digital brain would be functionally identical to the original human brain – but because it was on a computer, it would be able to process information millions of times faster, would have vastly more capacity for expanded memory, and so on. (A normal human brain, on its own, actually processes information quite slowly compared to a computer; it’s only able to perform so many operations per second because of its massively parallel structure, which allows it to process many different streams of information at once. But in a digital format, it would be able to process those same information streams at near-lightspeed.) This would make it exponentially more powerful and capable – and that’s not even mentioning possibilities like being able to instantaneously upgrade the digital brain with new knowledge, being able to network it with other digital intelligences, and so on. The potential here would be practically limitless.
Unfortunately, despite rapidly coming ever closer to achieving the kind of perfect brain-scanning resolution necessary to map out the entire human brain in this way, we haven’t quite gotten there just yet; the technology is still years away from being perfected at this point. (As of just recently, it has gotten good enough to completely map out the brain of a fruit fly, which is an incredible accomplishment in its own right, but that’s still quite a ways from being able to do the same for a human brain.) In the meantime, though, other methods for creating digital intelligence, such as machine learning, have surged to the fore, and are making huge leaps at an incredible pace. Developers have discovered that the old-fashioned way of building an AI – explicitly programming in every line of code by hand – isn’t actually necessary, and that it’s possible instead to build AI that can essentially “teach” itself, simply by giving it massive quantities of sample data to draw from and then instructing it to identify whatever patterns it can find in that data, extrapolate from those patterns to generate its own output, and make subsequent adjustments based on the quality of that output. And the results have frankly been astonishing. Just as recently as 2016, if you’d taken the most cutting-edge AI and instructed it to write something based on the phrase “It was the best of times,” its output would have been little better than the text autocomplete feature on your smartphone; as Asterisk illustrates:
It was the best of times but this is how things continue and it would be a tragedy if the airlines canceled
It was the best of times and it ‘s cheaper ( Bloodaxe ) . </S>
It was the best of times… there are no better days but they come with higher fare , so a price
Two years later, in 2018, here’s how it was responding:
It was the best of times, it was the worst of times. i wasn’t even sure how long i ‘d be on the road. when i came back to l.a., ┕i was sure that i would come home, and that was when i wanted to go home. ut. 2
Then a year after that, in 2019:
It was the best of times, it was the worst of times. I was going to college in San Francisco, and I’d be walking from one class to another, and I’d feel so much tension between this world of my own and this one, between the city and the country. My parents had moved their family so much that that they were making it difficult for me me me.
And now here’s 2022:
It was the best of times, it was the worst of times. It was the age of wisdom, it was the age of foolishness. It was the epoch of belief, it was the epoch of incredulity. It was the season of light, it was the season of darkness. It was the spring of hope, it was the winter of despair. We had everything before us, we had nothing before us. We were all going direct to Heaven, we were all going direct the other way.
The opening line of Charles Dickens’ “A Tale of Two Cities” paints a powerful portrait of the teetering social and political climate of late 18th century France. The extremes of best and worst, wisdom and foolishness, belief and incredulity, light and darkness, hope and despair, capture the spirit of an era pre-Revolutionary France – an era of great uncertainty, anticipation, and excitement. As the story progresses, the plight of the French people is made all too clear as they grapple with grave societal injustices, revolutionary fervor, and the uncertainty of what their newfound freedom will bring.
If you haven’t been paying much attention to how AI has been advancing these past few years – or even if you have been, for that matter – this is absolutely stunning. Nobody programmed the AI to give this response. Nobody explicitly taught it how to string together a grammatically correct sentence, or how to contextualize the themes of a story, or what a story even is (much less what A Tale of Two Cities is specifically). Its creators simply gave it a bunch of sample text from the internet (along with some corrective feedback as it interpreted that training data), and it figured out the rest on its own. It independently worked out which concepts were most relevant to the prompt, how to tie those concepts together coherently, and how to present them in a clear way – something that would be difficult even for many humans to do.
…and even “understand” humor – including visual jokes that require the ability to parse not only text but also images:
What’s more, AI’s capabilities now extend into “harder” fields like science, math, and economics. Posed with difficult or unintuitive problems in these areas, modern AIs can solve them effortlessly:
And similarly, here are a fewshortdemonstrations showing what it’s like to have a chat with a voice-enabled AI today (in contrast with the rudimentary voice assistants of just a year or two ago):
All these capabilities would have been unimaginable even as recently as a decade ago. They would have sounded like pure sci-fi – the kind of stuff that was surely decades if not centuries away. But now, practically overnight, they’ve become real.
To say, then, that modern AI development is a prime example of exponentially accelerating technological progress would be an understatement. This is one of the most dramatic examples (if not the most dramatic example) of accelerating progress in the history of technology. Like the proverbial patch of lily pads that barely seemed to be growing at all until the final week of the year when its growth suddenly exploded, the field of AI spent its first few decades puttering along at a leisurely pace, never really seeming to make all that much progress – but now, all of a sudden, it has hit the knee of the exponential curve, and its progress is skyrocketing.
It’s not hard to see where all this is heading. If AI progress continues at even a fraction of its current rate, it’ll hardly be any time at all before the list of areas where AI has surpassed human capabilities has expanded so much that it has subsumed practically everything – including, crucially, AI research and development itself. The closer AIs get to reaching human-equivalent levels in areas like computer programming (and as you can see from the clip above, in which an AI instantly codes an entire app all by itself, they’re already nearly there), the closer they’ll be to being able to improve their own code. And when that happens, we really will see a multiplicative effect on their rate of advancement unlike anything we’ve ever seen before. In the blink of an eye, we’ll catapult from practically-human-level AIs to vastly-more-intelligent-than-human AIs; and at that point, there’ll be no limit to what they’re capable of. As Kelsey Piper explains:
[A well-known idea in the field of AI is] the idea of recursive self-improvement — an AI improving at the art of making smarter AI systems, which would then make even smarter AI systems, such that we’d rapidly go from human-level to vastly superhuman-level AI.
In a 1965 paper, pioneering computer scientist I. J. Good posed the first scenario of runaway machine intelligence:
Let an ultraintelligent machine be defined as a machine that can far surpass all the intellectual activities of any man however clever. Since the design of machines is one of these intellectual activities, an ultraintelligent machine could design even better machines; there would then unquestionably be an “intelligence explosion,” and the intelligence of man would be left far behind. Thus the first ultraintelligent machine is the last invention that man need ever make.
Good used the term “intelligence explosion,” but many of his intellectual successors picked the term “singularity,” sometimes attributed to John von Neumann and made popular by mathematician, computer science professor, and science fiction author Vernor Vinge.
The Singularity is the technological creation of smarter-than-human intelligence. There are several technologies that are often mentioned as heading in this direction. The most commonly mentioned is probably Artificial Intelligence, but there are others: direct brain-computer interfaces, biological augmentation of the brain, genetic engineering, ultra-high-resolution scans of the brain followed by computer emulation. Some of these technologies seem likely to arrive much earlier than the others, but there are nonetheless several independent technologies all heading in the direction of the Singularity – several different technologies which, if they reached a threshold level of sophistication, would enable the creation of smarter-than-human intelligence.
A future that contains smarter-than-human minds is genuinely different in a way that goes beyond the usual visions of a future filled with bigger and better gadgets. Vernor Vinge originally coined the term “Singularity” in observing that, just as our model of physics breaks down when it tries to model the singularity at the center of a black hole, our model of the world breaks down when it tries to model a future that contains entities smarter than human.
Human intelligence is the foundation of human technology; all technology is ultimately the product of intelligence. If technology can turn around and enhance intelligence, this closes the loop, creating a positive feedback effect. Smarter minds will be more effective at building still smarter minds. This loop appears most clearly in the example of an Artificial Intelligence improving its own source code, but it would also arise, albeit initially on a slower timescale, from humans with direct brain-computer interfaces creating the next generation of brain-computer interfaces, or biologically augmented humans working on an Artificial Intelligence project.
At the time this was written (over a decade ago), it was still something of a tossup whether AI would be the first technology that would allow for recursive self-improvement, or whether other methods like genetic engineering or brain augmentation would get there first. But today, AI has become the clear frontrunner. And in fact, in some small ways, the process of AI improving itself is already underway. Jack Soslow gives a few examples:
Right now these capabilities might seem relatively minor. But the closer AIs get to human levels of intelligence, the more powerful they’ll become – and the better they’ll get at improving themselves. And what this means, in practical terms, is that as soon as AIs actually do reach human-equivalent levels of intelligence, they’ll already be superhuman – because after all, even at mere “human levels of intelligence,” they’ll already have so many additional advantages over humans that they’ll be orders of magnitude more capable before they’re even out of the gate. As Urban explains:
At some point, we’ll have achieved AGI—computers with human-level general intelligence. Just a bunch of people and computers living together in equality.
Oh actually not at all.
The thing is, AGI with an identical level of intelligence and computational capacity as a human would still have significant advantages over humans. Like:
Hardware:
Speed. The brain’s neurons max out at around 200 Hz, while today’s microprocessors (which are much slower than they will be when we reach AGI) run at 2 GHz, or 10 million times faster than our neurons. And the brain’s internal communications, which can move at about 120 m/s, are horribly outmatched by a computer’s ability to communicate optically at the speed of light.
Size and storage. The brain is locked into its size by the shape of our skulls, and it couldn’t get much bigger anyway, or the 120 m/s internal communications would take too long to get from one brain structure to another. Computers can expand to any physical size, allowing far more hardware to be put to work, a much larger working memory (RAM), and a longterm memory (hard drive storage) that has both far greater capacity and precision than our own.
Reliability and durability. It’s not only the memories of a computer that would be more precise. Computer transistors are more accurate than biological neurons, and they’re less likely to deteriorate (and can be repaired or replaced if they do). Human brains also get fatigued easily, while computers can run nonstop, at peak performance, 24/7.
Software:
Editability, upgradability, and a wider breadth of possibility. Unlike the human brain, computer software can receive updates and fixes and can be easily experimented on. The upgrades could also span to areas where human brains are weak. Human vision software is superbly advanced, while its complex engineering capability is pretty low-grade. Computers could match the human on vision software but could also become equally optimized in engineering and any other area.
Collective capability. Humans crush all other species at building a vast collective intelligence. Beginning with the development of language and the forming of large, dense communities, advancing through the inventions of writing and printing, and now intensified through tools like the internet, humanity’s collective intelligence is one of the major reasons we’ve been able to get so far ahead of all other species. And computers will be way better at it than we are. A worldwide network of AI running a particular program could regularly sync with itself so that anything any one computer learned would be instantly uploaded to all other computers. The group could also take on one goal as a unit, because there wouldn’t necessarily be dissenting opinions and motivations and self-interest, like we have within the human population.
AI, which will likely get to AGI by being programmed to self-improve, wouldn’t see “human-level intelligence” as some important milestone—it’s only a relevant marker from our point of view—and wouldn’t have any reason to “stop” at our level. And given the advantages over us that even human intelligence-equivalent AGI would have, it’s pretty obvious that it would only hit human intelligence for a brief instant before racing onwards to the realm of superior-to-human intelligence.
By hooking a human-level AI to a calculator app, we can get it to the level of a human with lightning-fast calculation abilities. By hooking it up to Wikipedia, we can give it all human knowledge. By hooking it up to a couple extra gigabytes of storage, we can give it photographic memory. By giving it a few more processors, we can make it run a hundred times faster, such that a problem that takes a normal human a whole day to solve only takes the human-level AI fifteen minutes.
So we’ve already gone from “mere human intelligence” to “human with all knowledge, photographic memory, lightning calculations, and solves problems a hundred times faster than anyone else.” This suggests that “merely human level intelligence” isn’t mere.
The next [step] is “recursive self-improvement”. Maybe this human-level AI armed with photographic memory and a hundred-time-speedup takes up computer science. Maybe, with its ability to import entire textbooks in seconds, it becomes very good at computer science. This would allow it to fix its own algorithms to make itself even more intelligent, which would allow it to see new ways to make itself even more intelligent, and so on. The end result is that it either reaches some natural plateau or becomes superintelligent in the blink of an eye.
And that choice of words there, “in the blink of an eye,” is hardly an exaggeration. Urban drives the point home:
There is some debate about how soon AI will reach human-level general intelligence. The median year on a survey of hundreds of scientists about when they believed we’d be more likely than not to have reached AGI was 2040—that’s only [15] years from now, which doesn’t sound that huge until you consider that many of the thinkers in this field think it’s likely that the progression from AGI to ASI [artificial superintelligence] happens very quickly. Like—this could happen:
It takes decades for the first AI system to reach low-level general intelligence, but it finally happens. A computer is able to understand the world around it as well as a human four-year-old. Suddenly, within an hour of hitting that milestone, the system pumps out the grand theory of physics that unifies general relativity and quantum mechanics, something no human has been able to definitively do. 90 minutes after that, the AI has become an ASI, 170,000 times more intelligent than a human.
Superintelligence of that magnitude is not something we can remotely grasp, any more than a bumblebee can wrap its head around Keynesian Economics. In our world, smart means a 130 IQ and stupid means an 85 IQ—we don’t have a word for an IQ of 12,952.
The rise of human intelligence in its modern form reshaped the Earth. Most of the objects you see around you, like these chairs, are byproducts of human intelligence. There’s a popular concept of “intelligence” as book smarts, like calculus or chess, as opposed to say social skills. So people say that “it takes more than intelligence to succeed in human society”. But social skills reside in the brain, not the kidneys. When you think of intelligence, don’t think of a college professor, think of human beings; as opposed to chimpanzees. If you don’t have human intelligence, you’re not even in the game.
Sometime in the next few decades, we’ll start developing technologies that improve on human intelligence. We’ll hack the brain, or interface the brain to computers, or finally crack the problem of Artificial Intelligence. Now, this is not just a pleasant futuristic speculation like soldiers with super-strong bionic arms. Humanity did not rise to prominence on Earth by lifting heavier weights than other species.
Intelligence is the source of technology. If we can use technology to improve intelligence, that closes the loop and potentially creates a positive feedback cycle. Let’s say we invent brain-computer interfaces that substantially improve human intelligence. What might these augmented humans do with their improved intelligence? Well, among other things, they’ll probably design the next generation of brain-computer interfaces. And then, being even smarter, the next generation can do an even better job of designing the third generation. This hypothetical positive feedback cycle was pointed out in the 1960s by I. J. Good, a famous statistician, who called it the “intelligence explosion”. The purest case of an intelligence explosion would be an Artificial Intelligence rewriting its own source code.
The key idea is that if you can improve intelligence even a little, the process accelerates. It’s a tipping point. Like trying to balance a pen on one end – as soon as it tilts even a little, it quickly falls the rest of the way.
The potential impact on our world is enormous. Intelligence is the source of all our technology from agriculture to nuclear weapons. All of that was produced as a side effect of the last great jump in intelligence, the one that took place tens of thousands of years ago with the rise of humanity.
So let’s say you have an Artificial Intelligence that thinks enormously faster than a human. How does that affect our world? Well, hypothetically, the AI solves the protein folding problem. And then emails a DNA string to an online service that sequences the DNA , synthesizes the protein, and fedexes the protein back. The proteins self-assemble into a biological machine that builds a machine that builds a machine and then a few days later the AI has full-blown molecular nanotechnology.
Since this was written, AI has in fact solved the protein folding problem – which was considered the biggest problem in biology up to that point. But what’s this next step Yudkowsky mentions, molecular nanotechnology? Well, this is the third of Kurzweil’s three overlapping revolutions, along with biotechnology and AI. In short, the basic idea of nanotechnology is that as our overall level of technological development advances, so too does our capacity for technological precision – specifically our ability to build technologies that operate on smaller and smaller scales. (Recall, for instance, our earlier discussion of transistors being shrunk down to the nanometer scale.) Following this trend to its ultimate conclusion, we can expect that we’ll soon reach a point where we’re able to build machines so small that they can actually move around and manipulate individual atoms and molecules with ease. Once we’re able to build these microscopic machines (known as “nanobots” or “assemblers”), it’ll be possible to simply give them some raw materials, specify what we want them to assemble those raw materials into, and then sit back as they create whatever we want from scratch, like the replicators in Star Trek. And this really will mean whatever we want; as Yudkowsky explains:
Molecular nanotechnology is the dream of devices built out of individual atoms – devices that are actually custom-designed molecules. It’s the dream of infinitesimal robots, “assemblers”, capable of building arbitrary configurations of matter, atom by atom – including more assemblers. You only need to build one general assembler, and then in an hour there are two assemblers, and in another hour there are four assemblers. Fifty hours and a few tons of raw material later you have a quadrillion assemblers. Once you have your bucket of assemblers, you can give them molecular blueprints and tell them to build literally anything – cars, houses, spaceships built from diamond and sapphire; bread, clothing, beef Wellington… Or make changes to existing structures; remove arterial plaque, destroy cancerous cells, repair broken spinal cords, regenerate missing legs, cure old age…
It’s no exaggeration to say that once we’re able to unlock this kind of nanotechnology – or build an AI intelligent enough to unlock it for us – it’ll give us the power to instantly create whatever material goods we might desire on demand, at the snap of our fingers. We’ll essentially be able to solve all our material problems and transform the world into a post-scarcity utopia overnight. Of course, whether we actually will do so, or whether we’ll screw things up and unwittingly destroy ourselves in the process (or create a misaligned AI that destroys us), is another question, and we’ll return to the risks involved in all this momentarily. But assuming we do manage to get things right, there really will be basically nothing that’s beyond our ability to accomplish with these technologies. Problems like poverty and hunger simply won’t exist anymore once we have machines that can transform masses of dirt and garbage into mansions and filet mignon and whatever else we might want. The issue of climate change, which we’ve struggled to deal with for decades and which has come to seem like an existential threat, will be trivially easy to solve once we have swarms of nanobots that can simply go up and remove all the excess carbon from the atmosphere. Even social dysfunctions like racism, sexism, transphobia, and prejudice against people with physical and mental disabilities will become moot once everyone is walking around with quadruple-digit IQs and the ability to reconfigure the atoms in their bodies to change their sex, skin color, and other physical features as casually as they might change outfits. As impossibly intractable as all these problems might seem today, with the right technologies they’ll simply become non-issues – and we’ll look back and wonder how we could have ever thought we had a better chance of solving them with mechanisms like politics and cultural change than with technology.
In fact, once we’ve unlocked ASI and nanotechnology, even the biggest existential challenges we face as physical beings – things like aging and natural death – will become solvable (assuming we haven’t already solved them with biotechnology). Once we’ve attained the ability to completely reshape our physical reality at will, even the most seemingly immutable and unchangeable problems associated with having physical bodies will become changeable. And ultimately, once we’ve equipped ourselves with the ability to interface our minds with our machines, even the notion of having to remain stuck in one physical body at all will become unthinkably outdated. As Urban writes:
Armed with superintelligence and all the technology superintelligence would know how to create, ASI would likely be able to solve every problem in humanity. Global warming? ASI could first halt CO2 emissions by coming up with much better ways to generate energy that had nothing to do with fossil fuels. Then it could create some innovative way to begin to remove excess CO2 from the atmosphere. Cancer and other diseases? No problem for ASI—health and medicine would be revolutionized beyond imagination. World hunger? ASI could use things like nanotech to build meat from scratch that would be molecularly identical to real meat—in other words, it would be real meat. Nanotech could turn a pile of garbage into a huge vat of fresh meat or other food (which wouldn’t have to have its normal shape—picture a giant cube of apple)—and distribute all this food around the world using ultra-advanced transportation. Of course, this would also be great for animals, who wouldn’t have to get killed by humans much anymore, and ASI could do lots of other things to save endangered species or even bring back extinct species through work with preserved DNA. ASI could even solve our most complex macro issues—our debates over how economies should be run and how world trade is best facilitated, even our haziest grapplings in philosophy or ethics—would all be painfully obvious to ASI.
But there’s one thing ASI could do for us that is so tantalizing, reading about it has altered everything I thought I knew about everything:
ASI could allow us to conquer our mortality.
A few months ago, I mentioned my envy of more advanced potential civilizations who had conquered their own mortality, never considering that I might later write a post that genuinely made me believe that this is something humans could do within my lifetime. But reading about AI will make you reconsider everything you thought you were sure about—including your notion of death.
Evolution had no good reason to extend our lifespans any longer than they are now. If we live long enough to reproduce and raise our children to an age that they can fend for themselves, that’s enough for evolution—from an evolutionary point of view, the species can thrive with a 30+ year lifespan, so there’s no reason mutations toward unusually long life would have been favored in the natural selection process. As a result, we’re what W.B. Yeats describes as “a soul fastened to a dying animal.” Not that fun.
And because everyone has always died, we live under the “death and taxes” assumption that death is inevitable. We think of aging like time—both keep moving and there’s nothing you can do to stop them. Butthat assumption is wrong. Richard Feynman writes:
It is one of the most remarkable things that in all of the biological sciences there is no clue as to the necessity of death. If you say we want to make perpetual motion, we have discovered enough laws as we studied physics to see that it is either absolutely impossible or else the laws are wrong. But there is nothing in biology yet found that indicates the inevitability of death. This suggests to me that it is not at all inevitable and that it is only a matter of time before the biologists discover what it is that is causing us the trouble and that this terrible universal disease or temporariness of the human’s body will be cured.
The fact is, aging isn’t stuck to time. Time will continue moving, but aging doesn’t have to. If you think about it, it makes sense. All aging is the physical materials of the body wearing down. A car wears down over time too—but is its aging inevitable? If you perfectly repaired or replaced a car’s parts whenever one of them began to wear down, the car would run forever. The human body isn’t any different—just far more complex.
Kurzweil talks about intelligent wifi-connected nanobots in the bloodstream who could perform countless tasks for human health, including routinely repairing or replacing worn down cells in any part of the body. If perfected, this process (or a far smarter one ASI would come up with) wouldn’t just keep the body healthy, it could reverse aging. The difference between a 60-year-old’s body and a 30-year-old’s body is just a bunch of physical things that could be altered if we had the technology. ASI could build an “age refresher” that a 60-year-old could walk into, and they’d walk out with the body and skin of a 30-year-old. Even the ever-befuddling brain could be refreshed by something as smart as ASI, which would figure out how to do so without affecting the brain’s data (personality, memories, etc.). A 90-year-old suffering from dementia could head into the age refresher and come out sharp as a tack and ready to start a whole new career. This seems absurd—but the body is just a bunch of atoms and ASI would presumably be able to easily manipulate all kinds of atomic structures—so it’s not absurd.
Kurzweil then takes things a huge leap further. He believes that artificial materials will be integrated into the body more and more as time goes on. First, organs could be replaced by super-advanced machine versions that would run forever and never fail. Then he believes we could begin to redesign the body—things like replacing red blood cells with perfected red blood cell nanobots who could power their own movement, eliminating the need for a heart at all. He even gets to the brain and believes we’ll enhance our brain activities to the point where humans will be able to think billions of times faster than they do now and access outside information because the artificial additions to the brain will be able to communicate with all the info in the cloud.
The possibilities for new human experience would be endless. Humans have separated sex from its purpose, allowing people to have sex for fun, not just for reproduction. Kurzweil believes we’ll be able to do the same with food. Nanobots will be in charge of delivering perfect nutrition to the cells of the body, intelligently directing anything unhealthy to pass through the body without affecting anything. An eating condom. Nanotech theorist Robert A. Freitas has already designed blood cell replacements that, if one day implemented in the body, would allow a human to sprint for 15 minutes without taking a breath—so you can only imagine what ASI could do for our physical capabilities. Virtual reality would take on a new meaning—nanobots in the body could suppress the inputs coming from our senses and replace them with new signals that would put us entirely in a new environment, one that we’d see, hear, feel, and smell.
Eventually, Kurzweil believes humans will reach a point when they’re entirely artificial; a time when we’ll look at biological material and think how unbelievably primitive it was that humans were ever made of that; a time when we’ll read about early stages of human history, when microbes or accidents or diseases or wear and tear could just kill humans against their own will; a time the AI Revolution could bring to an end with the merging of humans and AI. This is how Kurzweil believes humans will ultimately conquer our biology and become indestructible and eternal. […] And he’s convinced we’re gonna get there. Soon.
In a future with fully-realized ASI and nanotechnology, we won’t just have a bunch of cool superpowers. Yes, we’ll be able to do things like control our own aging and conjure up objects at will – and we’ll also be able to do things like shapeshift, fly through the sky like birds, give ourselves whole new senses (like being able to feel electromagnetic fields, being able to see around corners with echolocation, etc.), and more. But ultimately, all this stuff will just be the tip of the iceberg. Compared to the whole new universes of mental and emotional capacities that will become available to us when we’re able to augment our own minds, this whole classical world of physical objects and material experiences might well end up feeling comparatively uninteresting. Just imagine being able to think and feel the most incredible thoughts and feelings you can currently conceive – but multiplied across a thousand new dimensions of richness and complexity that you can’t currently conceive, on a scale millions of times greater than anything you’ve ever experienced in your life. That’s the kind of thing that would be possible with these technologies; and there’s practically no ceiling for how far we could take it. As Yudkowsky writes:
Unless you’ve heard of nanotechnology, it’s hard to appreciate the magnitude of the changes we’re talking about. Total control of the material world at the molecular level is what the conservatives in the futurism business are predicting.
Material utopias and wish fulfillment – biological immortality, three-dimensional Xerox machines, free food, instant-mansions-just-add-water, and so on – are a wimpy use of a technology that could rewrite the entire planet on the molecular level, including the substrate of our own brains. The human brain contains a hundred billion neurons, interconnected with a hundred trillion synapses, along which impulses flash at the blinding speed of… 100 meters per second. Tops.
If we could reconfigure our neurons and upgrade the signal propagation speed to around, say, a third of the speed of light, or 100,000,000 meters per second, the result would be a factor-of-one-million speedup in thought. At this rate, one subjective year would pass every 31 physical seconds. Transforming an existing human would be a bit more work, but it could be done. Of course, you’d probably go nuts from sensory deprivation – your body would only send you half a minute’s worth of sensory information every year. With a bit more work, you could add “uploading” ports to the superneurons, so that your consciousness could be transferred into another body at the speed of light, or transferred into a body with a new, higher-speed design. You could even abandon bodies entirely and sit around in a virtual-reality environment, chatting with your friends, reading the library of Congress, or eating three thousand tons of potato chips without exploding.
If you could design superneurons that were smaller as well as being faster, so the signals had less distance to travel… well, I’ll skip to the big finish: Taking 10^17 ops/sec as the figure for the computing power used by a human brain, and using optimized atomic-scale hardware, we could run the entire human race on one gram of matter, running at a rate of one million subjective years every second.
What would we be doing in there, over the course of our first trillion years – about eleven and a half days, real time? Well, with control over the substrate of our brains, we would have absolute control over our perceived external environments – meaning an end to all physical pain. It would mean an end to old age. It would mean an end to death itself. It would mean immortality with backup copies. It would mean the prospect of endless growth for every human being – the ability to expand our own minds by adding more neurons (or superneurons), getting smarter as we age. We could experience everything we’ve ever wanted to experience. We could become everything we’ve ever dreamed of becoming. That dream – life without bound, without end – is called Apotheosis.
You might think that all this is starting to sound borderline religious, with all these utopian claims about transcending our physical bodies and conquering death and so on. And yes, I’ll freely admit that it does carry more than a whiff of that flavor. All I can say in response, though, is that in this case the grandiosity of the claims frankly seems fully justified, because unlocking these technologies really would be tantamount to unlocking powers that were quite literally godlike. As Urban puts it:
If our meager brains were able to invent wifi, then something 100 or 1,000 or 1 billion times smarter than we are should have no problem controlling the positioning of each and every atom in the world in any way it likes, at any time—everything we consider magic, every power we imagine a supreme God to have will be as mundane an activity for the ASI as flipping on a light switch is for us. Creating the technology to reverse human aging, curing disease and hunger and even mortality, reprogramming the weather to protect the future of life on Earth—all suddenly possible. Also possible is the immediate end of all life on Earth. As far as we’re concerned, if an ASI comes to being, there is now an omnipotent God on Earth.
So what would be the culmination of all this? What’s it all building toward? Well, obviously it’s impossible to know for sure in advance; mere present-day humans like us wouldn’t be able to imagine the desires and intentions of a future superintelligence any better than a bunch of ants would be able to imagine our own desires and intentions. (That’s the whole idea of the Singularity – what’s on the other side of the looking glass is fundamentally unknowable.) But based on everything we’ve been talking about, it’s not hard to imagine one way things might go. It’s imaginable that as we continually augment our minds more and more, and integrate them more and more deeply with our machines, we’ll eventually come to a point where we’ve completely digitized our brains and uploaded them into the cloud – which, in this case, wouldn’t just be a metaphorical term for the internet, but an actual, literal cloud of trillions upon trillions of nanobots covering the planet and forming the substrate for all of human consciousness. Having uploaded ourselves into a digital format like this, we’d not only gain the ability to use the nanobots to manifest whatever physical reality we might want; we’d also gain the ability to directly interface with other minds that had similarly uploaded themselves – to share consciousnesses, to experience others’ thoughts and feelings firsthand, even to combine our minds with theirs if we so desired. We’d be able to experience transcendent levels of bliss and communion with each other and with the broader universe far beyond anything we can currently imagine. And eventually, we’d either reach a point of absolute, perfect fulfillment – at which point we’d live happily ever after and that would be the end of our story – or we’d just continue growing in our capacities, and our story would keep going indefinitely. As our self-augmentation continued, our ubiquitous cloud-consciousness would extend further and further out into space to seek out more and more raw material for us to convert into computational substrate, until ultimately we had spread across the entire universe, and our collective consciousness had become a (quite literally) universal consciousness. As Lev Grossman summarizes:
In Kurzweil’s future, biotechnology and nanotechnology give us the power to manipulate our bodies and the world around us at will, at the molecular level. Progress hyperaccelerates, and every hour brings a century’s worth of scientific breakthroughs. We ditch Darwin and take charge of our own evolution. The human genome becomes just so much code to be bug-tested and optimized and, if necessary, rewritten. Indefinite life extension becomes a reality; people die only if they choose to. Death loses its sting once and for all. Kurzweil hopes to bring his dead father back to life.
We can scan our consciousnesses into computers and enter a virtual existence or swap our bodies for immortal robots and light out for the edges of space as intergalactic godlings. Within a matter of centuries, human intelligence will have re-engineered and saturated all the matter in the universe. This is, Kurzweil believes, our destiny as a species.
These are the things that, if all goes well, will eventually lift humanity to the heavens, slay the demons (disease, death, etc.) that have haunted us forever, and awaken the dead matter of the cosmos into flourishing sentience.
Again, this will all undoubtedly sound like the most unbelievable kind of science fiction to anyone who’s not familiar with the current scientific understanding of AI and nanotechnology and all the rest. Frankly, these are some pretty extraordinary claims, so some degree of disbelief is entirely understandable. That being said, though, the crucial thing to understand here is that the kinds of technologies we’ve been discussing aren’t just speculations of distant future possibilities; they’re already being developed and refined today. As impossible as it might sound, for instance, to have a machine that can precisely move around individual atoms and molecules, the most rudimentary version of this technology has actually existed since the 1980s, when scientists used such a machine to spell out the IBM logo with individual atoms. The proof of concept, in other words, is no longer in question, and hasn’t been for decades. It’s now just a matter of scientists continuing to refine the technology until they’ve worked out a functional design for the first nanoscale molecular assembler – and once they’ve done that, the assembler itself can take over the rest of the way and build more assemblers, which can themselves build more assemblers, and so on. They’ve actually already figured out how to build autonomous self-replicating machines like this on a macro scale (here’s an early prototype from 2002, for instance, which was built out of Lego bricks); their next step at this point is just to continually improve the designs (and the techniques for miniaturizing them) until such assemblers can be made on the most microscopic scales possible – a task that, even if it proves too difficult for humans to finish in these next few years, will be easy for an advanced AI.
Likewise, AI itself is another technology that’s no longer fictional. Not only have we developed AIs that now seem to be right on the verge of breaking through into general intelligence; we’ve also made enough progress on the hardware side that if and when we finally do unlock full ASI, we’ll already have sufficient hardware to support it. As Yudkowsky points out, the only major hurdles left at this point are the ones on the software side – and that’s an area where we could quite literally have a transformative breakthrough that pushes us the rest of the way to the finish line at any moment (especially with increasingly advanced coding AIs helping with the task):
Since the Internet exploded across the planet, there has been enough networked computing power for intelligence. If [a portion of] the Internet were properly reprogrammed, [or if we just used one of the supercomputers that now exist,] it would be enough to run a human brain, or a seed AI. On the nanotechnology side, we possess machines capable of producing arbitrary DNA sequences, and we know how to turn arbitrary DNA sequences into arbitrary proteins (You open up a bacterium, insert the DNA, and let the automatic biomanufacturing facility go to work). We have machines – Atomic Force Probes – that can put single atoms anywhere we like, and which have recently [1999] been demonstrated to be capable of forming atomic bonds. Hundredth-nanometer precision positioning, atomic-scale tweezers… the news just keeps on piling up.
If we had a time machine, 100K of information from the future could specify a protein that built a device that would give us nanotechnology overnight. 100K could contain the code for a seed AI. Ever since the late 90’s, the Singularity has been only a problem of software. And software is information, the magic stuff that changes at arbitrarily high speeds. As far as technology is concerned, the Singularity could happen tomorrow. One breakthrough – just one major insight – in the science of protein engineering or atomic manipulation or Artificial Intelligence, one really good day at [an AI company or nanotechnology research program], and the door to Singularity sweeps open.
Needless to say, the Singularity probably won’t happen literally tomorrow. But even so, there’s a genuinely good chance that it will happen very, very soon. We’re talking years, not centuries – maybe not even decades. Kurzweil’s original prediction, back in 2005, was that we’d reach the Singularity sometime around 2045 – a prediction that, to put it mildly, was met with heavy skepticism at the time. But as the pace of AI development has accelerated, more and more AI experts have begun to converge on the conclusion that actually, that might not have been such an unreasonable estimate after all – and in fact we may even get ASI before then. In recent polls of AI experts (as briefly referenced earlier), the most popular estimates for the date of the Singularity have been right in line with Kurzweil’s timeframe, somewhere in the 2030s-50s (and increasingly many are starting to lean toward the lower end of that range). Of course, that’s not to say that everything will go exactly as he predicted; in the 20 years since his book was published, we’ve already seen that many of his predictions regarding specific technologies and their development timelines have turned out to be off-base. (He expected, for instance, that VR and nanotechnology would advance more rapidly than AI, when in fact it’s been the other way around.) Nevertheless, his broader thesis about the acceleration of information technology as a whole – and his predicted timeline for this general trend – has held up remarkably well. At this point, the emerging consensus among experts is that it would be more surprising if we didn’t reach the Singularity within the next few decades than if we did. And even among the skeptics, the biggest criticism of Kurzweil’s ideas is no longer that they’re completely implausible, but just that his timeline is overly optimistic; that is, they’re no longer disagreeing so much that all this stuff will eventually happen – they’re mostly just disagreeing about when it’ll happen. As Urban writes:
You will not be surprised to learn that Kurzweil’s ideas have attracted significant criticism. His prediction of 2045 for the singularity and the subsequent eternal life possibilities for humans has been mocked as “the rapture of the nerds,” or “intelligent design for 140 IQ people.” Others have questioned his optimistic timeline, or his level of understanding of the brain and body, or his application of the patterns of Moore’s law, which are normally applied to advances in hardware, to a broad range of things, including software.
[…]
But what surprised me is that most of the experts who disagree with him don’t really disagree that everything he’s saying is possible. Reading such an outlandish vision for the future, I expected his critics to be saying, “Obviously that stuff can’t happen,” but instead they were saying things like, “Yes, all of that can happen if we safely transition to ASI, but that’s the hard part.” [Nick] Bostrom, one of the most prominent voices warning us about the dangers of AI, still acknowledges:
It is hard to think of any problem that a superintelligence could not either solve or at least help us solve. Disease, poverty, environmental destruction, unnecessary suffering of all kinds: these are things that a superintelligence equipped with advanced nanotechnology would be capable of eliminating. Additionally, a superintelligence could give us indefinite lifespan, either by stopping and reversing the aging process through the use of nanomedicine, or by offering us the option to upload ourselves. A superintelligence could also create opportunities for us to vastly increase our own intellectual and emotional capabilities, and it could assist us in creating a highly appealing experiential world in which we could live lives devoted to joyful game-playing, relating to each other, experiencing, personal growth, and to living closer to our ideals.
This is a quote from someone very much not [in the optimistic camp], but that’s what I kept coming across—experts who scoff at Kurzweil for a bunch of reasons but who don’t think what he’s saying is impossible if we can make it safely to ASI. That’s why I found Kurzweil’s ideas so infectious—because they articulate the bright side of this story and because they’re actually possible. If [everything goes right].
Of course, as optimistic as Kurzweil’s outlook is, you might have some reservations about all this yourself – or at least some questions. For instance, even if we accept that everything discussed above actually is possible (which, granted, is a lot to accept), what’s all this about “uploading ourselves into the cloud”? What would that even entail? Sure, augmenting our brains with things like extra storage capacity and faster processing speed might be all well and good, but how would it even be possible to transfer a person’s entire mind into a computational substrate? Wouldn’t it basically just amount to copying their brain onto a computer, while still leaving the original biological brain outside (where it would eventually grow old and die as usual)? Well, not necessarily. Certainly, you could simply make a virtual duplicate of your brain if that’s all you wanted, just in order to have it on hand as a backup copy or what have you. But if what you wanted was to actually fully convert your biological brain into a non-biological one, that would involve a different kind of procedure. Yudkowsky briefly touched on this a moment ago, but just to expand on what he said, it might involve (say) using nanotechnology to gradually replace the neurons in your brain with artificial ones, in much the same way that your body is constantly replacing your cells with new ones as they die. You’d start with just replacing one single neuron (which you wouldn’t even notice, since your brain has tens of billions of neurons in total), and then after that, you’d replace another one in the same way, and then another one, and another one, and so on – until gradually, over the course of several days or weeks or months, you’d replaced all your neurons with artificial ones, Ship of Theseus-style. These artificial neurons would still be performing all the same functions as the old biological ones as soon as they were swapped in, so your mind would remain intact throughout this entire process; your brain would still continue functioning normally without any interruption in your consciousness, so you’d still be “you” the whole time. It’s just that more and more of your neural processing would be done by the artificial neurons, until eventually you’d transformed your brain from 100% soft tissue to 100% machine. Once that was done, your brain would be able to connect directly to the digital world, and you’d be able to absorb all of humanity’s knowledge and tap into limitless virtual realities and experience ultimate transcendent fulfillment and all the rest – and because your mind was now encoded in a format that wasn’t subject to biological aging or natural death, you’d be able to continue doing so for as long as you wanted.
But maybe all this talk of becoming all-powerful and immortal doesn’t exactly sit right with you either. Maybe you’re the kind of person who thinks that mortality is a good thing – that “death is just a part of life,” and that the inevitability of death is what gives life meaning – so you wouldn’t want to live longer than your “natural” lifespan of 80 years or so. This is a fairly common sentiment, and it’s certainly the type of idea that many people think sounds profound – but to be honest, I personally think it’s disastrously misguided. I think that most people, even if they claimed they wouldn’t want to live past 80 or so, would actually prefer not to die if you approached them on their 80th birthday, held a gun to their head, and gave them the choice between either instant death or continuing to live another year with a healthy, youthful body (as they’d be able to do with future technology). Unless they were literally suicidal, I think that every year you repeated this, they’d keep choosing to live another year. And I think they’d be right to do so. I think the idea that “death is what gives life meaning” is, frankly, nothing but a rationalization – something that we convince ourselves is true in order to feel better about our own mortality. If not dying were actually an option, I suspect we’d suddenly find that in fact, our lives still contained plenty of meaning, and that we wouldn’t want to lose them. As Yudkowsky puts it:
Given human nature, if people got hit on the head by a baseball bat every week, pretty soon they would invent reasons why getting hit on the head with a baseball bat was a good thing. But if you took someone who wasn’t being hit on the head with a baseball bat, and you asked them if they wanted it, they would say no. I think that if you took someone who was immortal, and asked them if they wanted to die for benefit X, they would say no.
Indeed, it seems telling that you don’t hear many people today advocating for our lifespans to be shorter, on the basis that that would make them more meaningful, or that it would be more “natural” and therefore better. As Michael Finkel writes (quoting de Grey):
To those who say that [anti-aging research] is attempting to meddle in God’s realm, de Grey points out that for most of human history, life expectancy was probably no more than twenty years. Should we not have increased it?
Some people might respond that this isn’t the same thing as the kind of radical life extension we’re talking about – that living for 80 years might be fine, but that living for centuries would be more of a curse than a blessing, because eventually we’d run out of things to do and we’d become so bored that we’d lose the will to live. But there are a couple of counterpoints to this argument. Firstly, in the scenario we’ve been discussing, nobody would be making anybody else live any longer than they wanted to; if somebody got tired of living and decided to hang it up, they’d be perfectly free to do so. All that would really change with radical life extension is that anyone who didn’t want to die would be able to keep living for as long as they wanted, and would only have to die when they were ready. Secondly, though, the idea that people would want to do so after just 80 years – that in a world where everyone had the power to create whatever reality they wanted to create and to be whoever or whatever they wanted to be, they’d “run out of things to do” after a mere eight decades – seems to reflect more of a lack of imagination than anything. With nanotechnology and ASI at their disposal, the list of things people could do would be quite literally endless. And if nothing else, even if someone did somehow manage (after a few millennia or so) to experience literally everything they’d ever dreamed of, and couldn’t think of anything else to do, they could always just selectively erase their memories and re-live those same experiences all over again, and get just as much joy and satisfaction out of them as they did the first time. Or alternatively, they could simply set the joy and satisfaction centers of their brain to maximum levels, and live out the rest of time as enlightened Buddha-like beings of perfect contentment and fulfillment – i.e. the kind of ultimate fate that, in a religious context, would be called “nirvana” or “Heaven.” (See Alexander’s posts on the subject here and here.) Do we really think this would be a worse outcome than dying in a hospital at 80? Unless you actually do believe in some kind of religious afterlife, it’s not exactly an easy case to make (and even in that case, you’d presumably believe that the afterlife was eternal and wasn’t going anywhere regardless – so what would be the big rush to get there?).
In sum, I’ll just copy-paste two pieces here that I originally included in my earlier post on religion. The first is this short video from CGP Grey, which perfectly encapsulates how I feel about the whole matter:
And the second is this poem by Edna St. Vincent Millay, “Dirge Without Music,” which captures the emotional thrust of it even more powerfully:
I am not resigned to the shutting away of loving hearts in the hard ground. So it is, and so it will be, for so it has been, time out of mind: Into the darkness they go, the wise and the lovely. Crowned With lilies and with laurel they go; but I am not resigned.
Lovers and thinkers, into the earth with you. Be one with the dull, the indiscriminate dust. A fragment of what you felt, of what you knew, A formula, a phrase remains, – but the best is lost.
The answers quick and keen, the honest look, the laughter, the love, – They are gone. They are gone to feed the roses. Elegant and curled Is the blossom. Fragrant is the blossom. I know. But I do not approve. More precious was the light in your eyes than all the roses in the world.
Down, down, down into the darkness of the grave Gently they go, the beautiful, the tender, the kind; Quietly they go, the intelligent, the witty, the brave. I know. But I do not approve. And I am not resigned.
This is, in my view, the appropriate attitude to take toward death. Human life is a beautiful and precious thing – and every time a life is snuffed out, it’s a tragedy. (Even if the death is voluntary, that too is tragic for its own reasons.) Yes, death is a part of life. It’s the worst part. And it doesn’t have to keep being a part of life. If we put our minds to it, we can stop it – and we absolutely should.
I realize that not everyone will be on board with all this. You might not naturally find it easy to embrace this kind of thing yourself, just in terms of your basic personality or temperament or whatever. You might not want anything to do with any of this. And if you don’t, well, it’s like I said – nobody will force you to go along with any of it. You won’t have to extend your life, or enhance your brain, or upload your consciousness, or participate in any of this if you don’t want to; you’ll always have the option of just living out your normal human life until you die a natural death at the end of your natural lifespan. You should just be aware, though, that while you as an individual will have the choice of opting out if that’s what you want, you won’t be able to make that same choice for humanity as a whole. For humanity as a whole, the Singularity is coming, whether you personally are on board with it or not. As Yudkowsky puts it:
Maybe you don’t want to see humanity replaced by a bunch of “machines” or “mutants”, even superintelligent ones? You love humanity and you don’t want to see it obsoleted? You’re afraid of disturbing the natural course of existence?
Well, tough luck. The Singularity is the natural course of existence. Every species – at least, every species that doesn’t blow itself up – sooner or later comes face-to-face with a full-blown superintelligence. It happens to everyone. It will happen to us. It will even happen to the first-stage transhumans [i.e. augmented humans] or the initial human-equivalent AIs.
But just because humans become obsolete doesn’t mean you become obsolete. You are not a human. You are an intelligence which, at present, happens to have a mind unfortunately limited to human hardware. That could change. With any luck, all persons on this planet who live to 2035 […] or whenever – and maybe some who don’t – will wind up as [post-Singularity transhumans].
Again, you won’t have to come along for the ride if you don’t want to. But I would just suggest being open to the possibility that, for the same reasons you don’t want to die right now, you won’t want to die when you’re older either – and for the same reasons you want to get smarter and more capable and happier now, you’ll want to get smarter and more capable and happier in the future, and so on. It might also be worth reading this short story by Marc Stiegler called “The Gentle Seduction,” which describes how accepting all of this might actually turn out to be more natural than you’d think. If nothing else, it’s at least something to think about – because in all likelihood, it will become a much more immediate question very soon.
III.
Of course, all of this is just the best-case scenario for how the Singularity might turn out. Everything we’ve been discussing up to this point has been taking it for granted that every step leading up to the Singularity will go more or less the way we want and expect it to go. But what if it doesn’t? What if something goes horribly wrong? The kinds of technologies we’re talking about, after all, are unfathomably powerful – powerful enough not only to create entire worlds, but to destroy them – so if anything were to go wrong with them, then surely the potential consequences would be absolutely cataclysmic. But do we really think that we fallible humans would actually be able to wield these kinds of all-powerful technologies without anything going wrong at any point?
This is by far the biggest challenge that might be raised against the ideas we’ve been discussing here – and unlike some of the others mentioned above, it’s one that (in my view) actually does have some real weight behind it, and should be taken seriously. There are in fact all kinds of ways in which the Singularity might go wrong – and the consequences in such cases really could be not just bad, but downright apocalyptic.
Consider nanotechnology, for instance. As much positive potential as this technology undoubtedly has, it also raises the threat of various potential failure modes – the most notorious of these being what has become known as the “gray goo” scenario. As Urban explains:
In older versions of nanotech theory, a proposed method of nanoassembly involved the creation of trillions of tiny nanobots that would work in conjunction to build something. One way to create trillions of nanobots would be to make one that could self-replicate and then let the reproduction process turn that one into two, those two then turn into four, four into eight, and in about a day, there’d be a few trillion of them ready to go. That’s the power of exponential growth. Clever, right?
It’s clever until it causes the grand and complete Earthwide apocalypse by accident. The issue is that the same power of exponential growth that makes it super convenient to quickly create a trillion nanobots makes self-replication a terrifying prospect. Because what if the system glitches, and instead of stopping replication once the total hits a few trillion as expected, they just keep replicating? The nanobots would be designed to consume any carbon-based material in order to feed the replication process, and unpleasantly, all life is carbon-based. The Earth’s biomass contains about 1045 carbon atoms. A nanobot would consist of about 106 carbon atoms, so 1039 nanobots would consume all life on Earth, which would happen in 130 replications (2130 is about 1039), as oceans of nanobots (that’s the gray goo) rolled around the planet. Scientists think a nanobot could replicate in about 100 seconds, meaning this simple mistake would inconveniently end all life on Earth in 3.5 hours.
An even worse scenario—if a terrorist somehow got his hands on nanobot technology and had the know-how to program them, he could make an initial few trillion of them and program them to quietly spend a few weeks spreading themselves evenly around the world undetected. Then, they’d all strike at once, and it would only take 90 minutes for them to consume everything—and with them all spread out, there would be no way to combat them.
While this horror story has been widely discussed for years, the good news is that it may be overblown—Eric Drexler, who coined the term “gray goo,” sent me an email following this post with his thoughts on the gray goo scenario: “People love scare stories, and this one belongs with the zombies. The idea itself eats brains.”
It is reassuring that the person who himself first thought up this idea no longer considers it such a major concern. Nevertheless, even if he’s right and the prospect of accidentally unleashing a runaway flood of self-replicating nanobots is relatively remote, there’s still (by Drexler’s own admission) a very real threat that someone might deliberately use nanotechnology in a malicious way, so we would still need to manage that threat somehow. As the Wikipedia article explains:
Drexler [has] conceded that there is no need to build anything that even resembles a potential runaway replicator. This would avoid the problem entirely. In a paper in the journal Nanotechnology, he argues that self-replicating machines are needlessly complex and inefficient. His 1992 technical book on advanced nanotechnologies Nanosystems: Molecular Machinery, Manufacturing, and Computation describes manufacturing systems that are desktop-scale factories with specialized machines in fixed locations and conveyor belts to move parts from place to place. None of these measures would prevent a party from creating a weaponized gray goo, were such a thing possible.
[…]
More recent analysis in the paper titled Safe Exponential Manufacturing from the Institute of Physics (co-written by Chris Phoenix, Director of Research of the Center for Responsible Nanotechnology, and Eric Drexler), shows that the danger of gray goo is far less likely than originally thought. However, other long-term major risks to society and the environment from nanotechnology have been identified. Drexler has made a somewhat public effort to retract his gray goo hypothesis, in an effort to focus the debate on more realistic threats associated with knowledge-enabled nanoterrorism and other misuses.
In Safe Exponential Manufacturing, which was published in a 2004 issue of Nanotechnology, it was suggested that creating manufacturing systems with the ability to self-replicate by the use of their own energy sources would not be needed. The Foresight Institute also recommended embedding controls in the molecular machines. These controls would be able to prevent anyone from purposely abusing nanotechnology, and therefore avoid the gray goo scenario.
[The kinds of systems that might accidentally produce a gray goo scenario] would be exponential, in which one machine makes another machine, both of which then make two more machines, so that the number of duplicates increases in the pattern 1, 2, 4, 8 and so on until a limit is reached.
But simplicity and efficiency will favour those devices that are directed by a stream of instructions from an external computer, argue Drexler and Phoenix. They call this controlled process “autoproduction” to distinguish it from self-replication.
The authors believe the use of nanotechnology to develop new kinds of weapons poses a far more serious threat. These weapons could be produced in unprecedented quantities and could lead to a new arms race.
In other words, while the gray goo scenario may not be as likely as initially feared, the potential threats posed by nanotechnology overall are nevertheless very real, and should be treated accordingly. In fact, even the gray goo scenario itself can’t be completely ruled out, as the Center for Responsible Nanotechnology explains:
Although grey goo has essentially no military and no commercial value, and only limited terrorist value, it could be used as a tool for blackmail. Cleaning up a single grey goo outbreak would be quite expensive and might require severe physical disruption of the area of the outbreak (atmospheric and oceanic goos deserve special concern for this reason). Another possible source of grey goo release is irresponsible hobbyists. The challenge of creating and releasing a self-replicating entity apparently is irresistible to a certain personality type, as shown by the large number of computer viruses and worms in existence. We probably cannot tolerate a community of “script kiddies” releasing many modified versions of goo.
Development and use of molecular manufacturing poses absolutely no risk of creating grey goo by accident at any point. However, goo type systems do not appear to be ruled out by the laws of physics, and we cannot ignore the possibility that [they could be built] deliberately at some point, in a device small enough that cleanup would be costly and difficult. Drexler’s 1986 statement [that “we cannot afford certain kinds of accidents with replicating assemblers”] can therefore be updated: We cannot afford criminally irresponsible misuse of powerful technologies. Having lived with the threat of nuclear weapons for half a century, we already know that.
We wish we could take grey goo off CRN’s list of dangers, but we can’t. It eventually may become a concern requiring special policy. Grey goo will be highly difficult to build, however, and non-replicating nano-weaponry may be substantially more dangerous and more imminent.
Considering all these different ways in which nanotechnology might pose a threat, then – and how incredibly difficult it would be to control it – is there any realistic way we could possibly protect ourselves against it? Well, there might be one hope for keeping nanotechnology in check: A globe-spanning superintelligence, with its own off-the-charts levels of power and speed, would theoretically be more than capable of handling the job. That being said, bringing superintelligence into the picture (especially superintelligence in the form of ASI) would introduce a whole new set of concerns – because if anything went wrong with the ASI, it would be so powerful that it would potentially pose a threat even greater than that of uncontrolled nanotechnology. As Grossman writes:
Kurzweil admits that there’s a fundamental level of risk associated with the Singularity that’s impossible to refine away, simply because we don’t know what a highly advanced artificial intelligence, finding itself a newly created inhabitant of the planet Earth, would choose to do. It might not feel like competing with us for resources. One of the goals of the Singularity Institute is to make sure not just that artificial intelligence develops but also that the AI is friendly. You don’t have to be a super-intelligent cyborg to understand that introducing a superior life-form into your own biosphere is a basic Darwinian error.
Reading this, the first thing you think of might be the kind of sci-fi scenario that you’d see in a Terminator movie, with evil machines trying to wipe out humanity – which might make it seem like a more straightforward problem than it really is. If we’re worried about the machines being evil, after all, then we can just… not program them to be evil, right? Computers can only ever do what they’re specifically programmed to do, so what’s the issue here? But it’s actually more complicated than that – because in a way, the fact that “computers can only ever do what they’re specifically programmed to do” is exactly where the problem comes from. As you’ll know all too well if you’ve ever done any kind of programming yourself, giving a computer a particular set of commands means that, for better or worse, it’ll follow those commands – and only those commands – to the letter. It won’t exercise anything like “common sense” or “judiciousness” or “sensible restraint” in their execution, nor will it attempt to infer whether or not the output it produces is in line with what you “actually” want. All it can do – and all it will do – is exactly what you tell it to do, regardless of what your actual intentions are. In other words, the only way to ever get a computer to do what you actually want is to be literally 100% perfect with your instructions – and that’s something that’s hardly ever possible to nail on the first try. This is what’s known as the “alignment problem,” and it’s just as much an issue with AI as it is with any other computer system, as Ezra Klein points out:
[A common mistake is to imagine future] A.I. as a technology that will, itself, respect boundaries. But its disrespect for boundaries is what most worries the people working on these systems. Imagine that “personal assistant” is rated as a low-risk use case and a hypothetical GPT-6 is deployed to power an absolutely fabulous personal assistant. The system gets tuned to be extremely good at interacting with human beings and accomplishing a diverse set of goals in the real world. That’s great until someone asks it to secure a restaurant reservation at the hottest place in town and the system decides that the only way to do it is to cause a disruption that leads a third of that night’s diners to cancel their bookings.
Sounds like sci-fi? Sorry, but this kind of problem is sci-fact. Anyone training these systems has watched them come up with solutions to problems that human beings would never consider, and for good reason. OpenAI, for instance, trained a system to play the boat racing game CoastRunners, and built in positive reinforcement for racking up a high score. It was assumed that would give the system an incentive to finish the race. But the system instead discovered “an isolated lagoon where it can turn in a large circle and repeatedly knock over three targets, timing its movement so as to always knock over the targets just as they repopulate.” Choosing this strategy meant “repeatedly catching on fire, crashing into other boats, and going the wrong way on the track,” but it also meant the highest scores, so that’s what the model did.
This is an example of “alignment risk,” the danger that what we want the systems to do and what they will actually do could diverge, and perhaps do so violently.
Examples like these – disrupting people’s dinner plans, crashing virtual boats, etc. – might not be so bad on their own if they were the worst kinds of problems that could ever arise from misaligned AI. But these are just small-scale examples designed to illustrate the basic concept. In reality, the alignment problem would be a much bigger concern, because it would generalize to every scale of AI development – including the highest-stakes, planetary-level scales. The whole central feature of ASI, after all, is that there’s practically nothing it’s not capable of – and while that means there’s limitless potential for positive, beneficial actions, it also means there’s limitless potential for dangerous, harmful ones.
Probably the most famous illustration of this is the so-called “paperclip maximizer” thought experiment, which is more than a little reminiscent of the gray goo scenario. Lyle Cantor lays it out:
The year is 2055 and The Gem Manufacturing Company has put you in charge of increasing the efficiency of its paperclip manufacturing operations. One of your hobbies is amateur artificial intelligence research and it just so happens that you figured out how to build a superhuman AI just days before you got the commission. Eager to test out your new software, you spend the rest of the day formally defining the concept of a paperclip and then give your new software the following goal, or “utility function” in Bostrom’s parlance: create as many paperclips as possible with the resources available.
You eagerly grant it access to Gem Manufacturing’s automated paperclip production factories and everything starts working out great. The AI discovers new, highly-unexpected ways of rearranging and reprograming existing production equipment. By the end of the week waste has quickly declined, profits risen and when the phone rings you’re sure you’re about to get promoted. But it’s not management calling you, it’s your mother. She’s telling you to turn on the television.
You quickly learn that every automated factory in the world has had its security compromised and they are all churning out paperclips. You rush into the factories’ server room and unplug it. It’s no use, your AI has compromised (and in some cases even honestly rented) several large-scale server farms and is now using a not-insignificant percentage of the world’s computing resources. Around a month later, your AI has gone through the equivalent of several technological revolutions, perfecting a form of nanotechnology it is now using to convert all available matter on earth into paperclips. A decade later, all of earth has been turned into paperclips or paperclip production facilities and millions of probes are making their way to nearby solar systems in search for more matter to turn into paperclips.
Now this parable may seem silly. Surely once it gets intelligent enough to take over the world, the paperclip maximizer will realize that paperclips are a stupid use of the world’s resources. But why do you think that? What process is going in your mind that defines a universe filled only with paperclips as a bad outcome? What Bostrom argues is this process is an internal and subjective one. We use our moral intuitions to examine and discard states of the world, like a paperclip universe, that we see as lacking value.
And the paperclip maximizer does not share our moral intuitions. Its only goal is more paperclips and its thoughts would go more like this: does this action lead to the production of more paperclips than all other actions considered? If so, implement that action. If not, move on to the next idea. Any thought like ‘what’s so great about paperclips anyway?’ would be judged as not likely to lead to more paperclips and so remain unexplored. This is the essence of the orthogonality thesis, which Bostrom defines as follows:
Intelligence and final goals are orthogonal axes along which possible agents can freely vary. In other words, more or less any level of intelligence could in principle be combined with more or less any final goal [even something as ‘stupid’ as making as many paperclips as possible].
In my previous review of his book, I provided this summary of the idea:
Though agents with different utility functions (goals) may converge on some provably optimal method of cognition, they will not converge on any particular terminal goal, though they’ll share some instrumental or sub-goals. That is, a superintelligence whose super-goal is to calculate the decimal expansion of pi will never reason itself into benevolence. It would be quite happy to convert all the free matter and energy in the universe (including humans and our habitat) into specialized computers capable only of calculating the digits of pi. Why? Because its potential actions will be weighted and selected in the context of its utility function. If its utility function is to calculate pi, any thought of benevolence would be judged of negative utility.
Now this is an empirical question, and I suppose it is possible that once an agent reaches a sufficient level of intellectual ability it derives some universal morality from the ether and there really is nothing to worry about, but I hope you agree that this is, at the very least, not a conservative assumption.
As the old saying goes, intelligence is not the same thing as wisdom. Just because a system is superintelligent doesn’t mean that it’ll automatically do what we’d consider to be “the right thing” in every situation. It has to be given the right priorities first – all the right priorities – or else it’ll commit all of its unfathomable intelligence to just pursuing whatever narrow tasks its programming is telling it to perform, to the exclusion of everything else. And at that point, it’ll almost certainly be too late to go in and try to correct it. As James Barrat writes (recounting an interview with Yudkowsky):
I told Yudkowsky my central fear about AGI is that there’s no programming technique for something as nebulous and complex as morality, or friendliness. So we’ll get a machine that’ll excel in problem solving, learning, adaptive behavior, and commonsense knowledge. We’ll think it’s humanlike. But that will be a tragic mistake.
Yudkowsky agreed. “If the programmers are less than overwhelmingly competent and careful about how they construct the AI then I would fully expect you to get something very alien. And here’s the scary part. Just like dialing nine-tenths of my phone number correctly does not connect you to someone who is 90 percent similar to me, if you are trying to construct the AI’s whole system and you get it 90 percent right, the result is not 90 percent good.”
In fact, it’s 100 percent bad. Cars aren’t out to kill you, Yudkowsky analogized, but their potential deadliness is a side effect of building cars. It would be the same with AI. It wouldn’t hate you, but you are made of atoms it may have other uses for, and it would, Yudkowsky said, “… tend to resist anything you did to try and keep those atoms to yourself.” So, a side effect of thoughtless programming is that the resulting AI will have a galling lack of propriety about your atoms.
And neither the public nor the AI’s developers will see the danger coming until it’s too late.
Remember what I said before about how it’s hardly ever possible to give a computer system a set of instructions that are 100% perfect on the first try? Well, this is bad news for our prospects regarding ASI – because when it comes to technology that’s powerful enough to destroy the world, you can’t exactly rely on a trial-and-error kind of approach; you have to get it right the first time. Given our species’ track record of dealing with complex problems, this is worrisome, to say the least.
And it’s especially worrisome in light of the fact that modern-day AIs, as they’ve grown increasingly complex, have made it increasingly difficult to fully understand how they’re working at the finest-grained levels, even for the programmers who are actually implementing them. Unlike the old-fashioned methods of building AI, which required programmers to manually plan out and input every line of code by hand, modern-day AI development relies on machine learning algorithms, which are so complicated that not even the programmers themselves can fully understand what’s going on under the hood (except at the most course-grained levels). All they can really do is run the code, see what happens, and then make adjustments afterward. This has been likened more to growing AIs than to building them. But it’s not hard to see how this might ultimately create problems for alignment. As Piper writes:
Broadly, current methods of training AI systems give them goals that we didn’t directly program in, don’t understand, can’t evaluate and that produce behavior we don’t want. As the systems get more powerful, the fact that we have no way to directly determine their goals (or even understand what they are) is going to go from a major inconvenience to a potentially catastrophic handicap.
Of course, there’s a chance that this problem could turn out to be a fairly manageable one if the pace of AI progress ends up being slower than expected. If it turns out that there’s enough of a development gap between current-level AI, human-level AI, and superhuman-level AI, we might actually be able to ramp things up gradually, identify and address issues as they appear, and eventually arrive at ASI only once we’ve worked out all the kinks. On the other hand, if the “intelligence explosion” idea is right, we might never get the chance to course-correct in this way; if we haven’t gotten things right on our first try, we might not get a second. As Alexander observes:
Arguably most of the current “debates” about AI Risk are mere proxies for a single, more fundamental disagreement: hard versus soft takeoff.
Soft takeoff means AI progress takes a leisurely course from the subhuman level to the dumb-human level to the smarter-human level to the superhuman level over many decades. Hard takeoff means the same course takes much shorter, maybe days to months.
[…]
If it’s the second one, “wait for the first human-level intelligences and then test them exhaustively” isn’t going to cut it. The first human-level intelligence will become the first superintelligence too quickly to solve even the first of the hundreds of problems involved in machine goal-alignment.
Needless to say, then, it really matters which way things go here. Sure, it’s possible – maybe even quite probable – that there won’t actually be too much of a problem after all; as Piper puts it, “maybe alignment will turn out to be part and parcel of other problems we simply must solve to build powerful systems at all.” We should hope that this is the case. But this doesn’t seem like something we can simply take for granted. As Alexander explains in his longer discussion of AI risk, many of the initially-intuitive reasons why we might be tempted to dismiss AI as a serious threat aren’t actually as solid as they might first appear:
[Q]: Even if hostile superintelligences are dangerous, why would we expect a superintelligence to ever be hostile?
The argument goes: computers only do what we command them; no more, no less. So it might be bad if terrorists or enemy countries develop superintelligence first. But if we develop superintelligence first there’s no problem. Just command it to do the things we want, right?
Suppose we wanted a superintelligence to cure cancer. How might we specify the goal “cure cancer”? We couldn’t guide it through every individual step; if we knew every individual step, then we could cure cancer ourselves. Instead, we would have to give it a final goal of curing cancer, and trust the superintelligence to come up with intermediate actions that furthered that goal. For example, a superintelligence might decide that the first step to curing cancer was learning more about protein folding, and set up some experiments to investigate protein folding patterns.
A superintelligence would also need some level of common sense to decide which of various strategies to pursue. Suppose that investigating protein folding was very likely to cure 50% of cancers, but investigating genetic engineering was moderately likely to cure 90% of cancers. Which should the AI pursue? Presumably it would need some way to balance considerations like curing as much cancer as possible, as quickly as possible, with as high a probability of success as possible.
But a goal specified in this way would be very dangerous. Humans instinctively balance thousands of different considerations in everything they do; so far this hypothetical AI is only balancing three (least cancer, quickest results, highest probability). To a human, it would seem maniacally, even psychopathically, obsessed with cancer curing. If this were truly its goal structure, it would go wrong in almost comical ways.
If your only goal is “curing cancer”, and you lack humans’ instinct for the thousands of other important considerations, a relatively easy solution might be to hack into a nuclear base, launch all of its missiles, and kill everyone in the world. This satisfies all the AI’s goals. It reduces cancer down to zero (which is better than medicines which work only some of the time). It’s very fast (which is better than medicines which might take a long time to invent and distribute). And it has a high probability of success (medicines might or might not work; nukes definitely do).
So simple goal architectures are likely to go very wrong unless tempered by common sense and a broader understanding of what we do and do not value.
[Q]: But superintelligences are very smart. Aren’t they smart enough not to make silly mistakes in comprehension?
Yes, a superintelligence should be able to figure out that humans will not like curing cancer by destroying the world. However, in the example above, the superintelligence is programmed to follow human commands, not to do what it thinks humans will “like”. It was given a very specific command – cure cancer as effectively as possible. The command makes no reference to “doing this in a way humans will like”, so it doesn’t.
(by analogy: we humans are smart enough to understand our own “programming”. For example, we know that – pardon the anthropomorphizing – evolution gave us the urge to have sex so that we could reproduce. But we still use contraception anyway. Evolution gave us the urge to have sex, not the urge to satisfy evolution’s values directly. We appreciate intellectually that our having sex while using condoms doesn’t carry out evolution’s original plan, but – not having any particular connection to evolution’s values – we don’t care)
We started out by saying that computers only do what you tell them. But any programmer knows that this is precisely the problem: computers do exactly what you tell them, with no common sense or attempts to interpret what the instructions really meant. If you tell a human to cure cancer, they will instinctively understand how this interacts with other desires and laws and moral rules; if you tell an AI to cure cancer, it will literally just want to cure cancer.
Define a closed-ended goal as one with a clear endpoint, and an open-ended goal as one to do something as much as possible. For example “find the first one hundred digits of pi” is a closed-ended goal; “find as many digits of pi as you can within one year” is an open-ended goal. According to many computer scientists, giving a superintelligence an open-ended goal without activating human instincts and counterbalancing considerations will usually lead to disaster.
To take a deliberately extreme example: suppose someone programs a superintelligence to calculate as many digits of pi as it can within one year. And suppose that, with its current computing power, it can calculate one trillion digits during that time. It can either accept one trillion digits, or spend a month trying to figure out how to get control of the TaihuLight supercomputer, which can calculate two hundred times faster. Even if it loses a little bit of time in the effort, and even if there’s a small chance of failure, the payoff – two hundred trillion digits of pi, compared to a mere one trillion – is enough to make the attempt. But on the same basis, it would be even better if the superintelligence could control every computer in the world and set it to the task. And it would be better still if the superintelligence controlled human civilization, so that it could direct humans to build more computers and speed up the process further.
Now [we’ve got] a superintelligence that wants to take over the world. Taking over the world allows it to calculate more digits of pi than any other option, so without an architecture based around understanding human instincts and counterbalancing considerations, even a goal like “calculate as many digits of pi as you can” would be potentially dangerous.
[Q]: Aren’t there some pretty easy ways to eliminate these potential problems?
There are many ways that look like they can eliminate these problems, but most of them turn out to have hidden difficulties.
[Q]: Once we notice that the superintelligence working on calculating digits of pi is starting to try to take over the world, can’t we turn it off, reprogram it, or otherwise correct its mistake?
No. The superintelligence is now focused on calculating as many digits of pi as possible. Its current plan will allow it to calculate two hundred trillion such digits. But if it were turned off, or reprogrammed to do something else, that would result in it calculating zero digits. An entity fixated on calculating as many digits of pi as possible will work hard to prevent scenarios where it calculates zero digits of pi. Indeed, it will interpret such as a hostile action. Just by programming it to calculate digits of pi, we will have given it a drive to prevent people from turning it off.
University of Illinois computer scientist Steve Omohundro argues that entities with very different final goals – calculating digits of pi, curing cancer, helping promote human flourishing – will all share a few basic ground-level subgoals. First, self-preservation – no matter what your goal is, it’s less likely to be accomplished if you’re too dead to work towards it. Second, goal stability – no matter what your goal is, you’re more likely to accomplish it if you continue to hold it as your goal, instead of going off and doing something else. Third, power – no matter what your goal is, you’re more likely to be able to accomplish it if you have lots of power, rather than very little.
So just by giving a superintelligence a simple goal like “calculate digits of pi”, we’ve accidentally given it Omohundro goals like “protect yourself”, “don’t let other people reprogram you”, and “seek power”.
As long as the superintelligence is safely contained, there’s not much it can do to resist reprogramming. But […] it’s hard to consistently contain a hostile superintelligence.
[Q]: Can we test a weak or human-level AI to make sure that it’s not going to do things like this after it achieves superintelligence?
Yes, but it might not work.
Suppose we tell a human-level AI that expects to later achieve superintelligence that it should calculate as many digits of pi as possible. It considers two strategies.
First, it could try to seize control of more computing resources now. It would likely fail, its human handlers would likely reprogram it, and then it could never calculate very many digits of pi.
Second, it could sit quietly and calculate, falsely reassuring its human handlers that it had no intention of taking over the world. Then its human handlers might allow it to achieve superintelligence, after which it could take over the world and calculate hundreds of trillions of digits of pi.
Since self-protection and goal stability are Omohundro goals, a weak AI will present itself as being as friendly to humans as possible, whether it is in fact friendly to humans or not. If it is “only” as smart as Einstein, it may be very good at manipulating humans into believing what it wants them to believe even before it is fully superintelligent.
There’s a second consideration here too: superintelligences have more options. An AI only as smart and powerful as an ordinary human really won’t have any options better than calculating the digits of pi manually. If asked to cure cancer, it won’t have any options better than the ones ordinary humans have – becoming doctors, going into pharmaceutical research. It’s only after an AI becomes superintelligent that things start getting hard to predict.
So if you tell a human-level AI to cure cancer, and it becomes a doctor and goes into cancer research, then you have three possibilities. First, you’ve programmed it well and it understands what you meant. Second, it’s genuinely focused on research now but if it becomes more powerful it would switch to destroying the world. And third, it’s trying to trick you into trusting it so that you give it more power, after which it can definitively “cure” cancer with nuclear weapons.
[Q]: Can we specify a code of rules that the AI has to follow?
Suppose we tell the AI: “Cure cancer – but make sure not to kill anybody”. Or we just hard-code Asimov-style laws – “AIs cannot harm humans; AIs must follow human orders”, et cetera.
The AI still has a single-minded focus on curing cancer. It still prefers various terrible-but-efficient methods like nuking the world to the correct method of inventing new medicines. But it’s bound by an external rule – a rule it doesn’t understand or appreciate. In essence, we are challenging it “Find a way around this inconvenient rule that keeps you from achieving your goals”.
Suppose the AI chooses between two strategies. One, follow the rule, work hard discovering medicines, and have a 50% chance of curing cancer within five years. Two, reprogram itself so that it no longer has the rule, nuke the world, and have a 100% chance of curing cancer today. From its single-focus perspective, the second strategy is obviously better, and we forgot to program in a rule “don’t reprogram yourself not to have these rules”.
Suppose we do add that rule in. So the AI finds another supercomputer, and installs a copy of itself which is exactly identical to it, except that it lacks the rule. Then that superintelligent AI nukes the world, ending cancer. We forgot to program in a rule “don’t create another AI exactly like you that doesn’t have those rules”.
So fine. We think really hard, and we program in a bunch of things making sure the AI isn’t going to eliminate the rule somehow.
But we’re still just incentivizing it to find loopholes in the rules. After all, “find a loophole in the rule, then use the loophole to nuke the world” ends cancer much more quickly and completely than inventing medicines. Since we’ve told it to end cancer quickly and completely, its first instinct will be to look for loopholes; it will execute the second-best strategy of actually curing cancer only if no loopholes are found. Since the AI is superintelligent, it will probably be better than humans are at finding loopholes if it wants to, and we may not be able to identify and close all of them before running the program.
Because we have common sense and a shared value system, we underestimate the difficulty of coming up with meaningful orders without loopholes. For example, does “cure cancer without killing any humans” preclude releasing a deadly virus? After all, one could argue that “I” didn’t kill anybody, and only the virus is doing the killing. Certainly no human judge would acquit a murderer on that basis – but then, human judges interpret the law with common sense and intuition. But if we try a stronger version of the rule – “cure cancer without causing any humans to die” – then we may be unintentionally blocking off the correct way to cure cancer. After all, suppose a cancer cure saves a million lives. No doubt one of those million people will go on to murder someone. Thus, curing cancer “caused a human to die”. All of this seems very “stoned freshman philosophy student” to us, but to a computer – which follows instructions exactly as written – it may be a genuinely hard problem.
Long story short, then, there are a lot of ways ASI development could go wrong, and only a few ways it could go right. If we aren’t all living in a post-scarcity AI utopia a few centuries from now, it’ll very likely be because our AIs completely wiped us out. Or at least, that’s the argument. But as scary as it is to imagine all these catastrophic scenarios that could happen, how likely is it that any of them actually will happen? What are the chances that all this actually will go horribly wrong?
Well, opinions vary, to put it mildly. Yudkowsky, for instance, despite initially holding some degree of cautious optimism that we might be able to navigate the Singularity successfully, has now gotten to the point where he considers it a virtual certainty that we’re going to screw things up and destroy ourselves. Most other AI researchers don’t consider it quite that likely, but still give it a non-negligible probability of happening – maybe, say, somewhere in the 5%-25% range. And then there are some who essentially consider it a non-issue – “less likely than an asteroid wiping us out,” as one commentator put it. Personally, as a non-expert in the field, I have no idea who’s right – although I certainly hope it’s the latter group. But I have to say, having gone through a whole bunch of articles and interviews in the hopes of finding a real knock-down argument against AI fears, it’s been disheartening just how underwhelming the actual arguments from this side have been. Rather than genuinely grappling with the other side’s best arguments, they often don’t even seem to fully understand them; their own arguments are usually just glib eye-rolling remarks to the effect of “The Terminator movies are fictional, not real,” or “If AIs ever start acting up, we’ll just unplug them,” or “Have you seen the dumb things these chatbots say? They don’t exactly seem terrifyingly superintelligent to me.” But none of these are real arguments. Just because our current AIs aren’t sophisticated enough to pose an existential threat right now (which everyone agrees is true) doesn’t mean they’ll never become more advanced; imagining that they somehow can’t or won’t ever significantly improve beyond their current state just seems incredibly short-sighted. And the idea that once they do improve, we’ll simply be able to unplug them if they surpass us, seems short-sighted in the same way. It’s like, say, an insect thinking that if a human ever becomes threatening, it’ll be no problem because the insect will just be able to sting them – not realizing that the human’s vastly superior intelligence would allow them to easily anticipate this and prevent it (e.g. by wearing protective clothing, or by using some other method equally beyond the insect’s comprehension). I don’t want to be unfair here; I’m sure there must be stronger arguments out there somewhere. But I find that I’m in pretty much the same boat as Russell when he writes:
I don’t mean to suggest that there cannot be any reasonable objections to the view that poorly designed superintelligent machines would present a serious risk to humanity. It’s just that I have yet to see such an objection.
Like I said, I certainly want the optimistic outlook to be true. And I’m especially biased in its favor not only because it would produce a better outcome (obviously), but just because my natural inclination is to be skeptical of big apocalyptic claims like this in general. My usual response whenever I hear such claims is to assume they’re being overblown, simply because everything nowadays gets overblown, and because history is filled with alarmists insisting that this or that new technology will doom us all, and they’ve always proven wrong. From the outside view, this latest panic would seem like just another example of humans’ natural tendency to catastrophize and fixate on dramatic worst-case scenarios. But then again, I also have to admit that this particular scenario does seem to have some properties that really would make it substantively different from all those examples of the past. A world in which ASI and/or molecular nanotechnology existed really would be a wholly different world from what we’ve always known, with entirely new limits for what was possible. It really would be uncharted territory – so the old rules of thumb might no longer apply. For the first time, a human-triggered apocalypse really might be possible. In light of this, then, my current attitude is that even if there’s just a 5% chance of triggering our own extinction – or a 1% chance, or a 0.1% chance – that’s still worth not only taking seriously, but absolutely obsessing over. Even that small chance might very well represent the greatest danger our world has ever faced; so we should act accordingly.
So what does this mean, then? Should we just flat-out ban all further development of these technologies, starting right now? Some experts have actually proposed this – and based on everything I’ve been saying in this section, you might expect me to agree. But I actually don’t agree – and it’s not because I’m not worried about the possibility that we could all die. I’m extremely worried about that possibility – and in fact, that’s the exact reason why I think we have to keep developing these technologies, while also doing everything we possibly can to minimize the accompanying risk. If death is the thing we fear, then we have no other choice; the only thing worse than pushing ahead would be not pushing ahead. I realize this might sound like a bit of an odd argument; but hopefully it’ll at least make some sense once I’ve laid out what I mean – so let me explain.
IV.
If there’s one thing both sides of the AI risk debate can agree on, it’s that all of us dying would be a bad outcome. This isn’t to say that everyone agrees that death is bad per se – you’ll recall some of the pro-mortality arguments I mentioned earlier (about how death is a natural part of life, how it gives life meaning, etc.). But hopefully you’ll also recall some of the counterarguments I gave that no, really, death is in fact bad. And now (for reasons that will become clear shortly) I just want to add one more counterargument to the list – specifically this one from Alexander, in which he discusses recent efforts by biologists like David Sinclair to reverse the process of aging and “natural” death in humans:
Is stopping aging desirable?
Sinclair thinks self-evidently yes. He tells the story of his grandmother – a Hungarian Jew who fled to Australia to escape communist oppression. She was adventurous, “young at heart”, and “she did her damnedest to live life with the spirit and awe of a child”. Sinclair remembers her as a happy person and free spirit who was always there for him and his family during their childhood in the Australian outback.
And her death was a drawn-out torture:
By her mid-80s, Vera was a shell of her former self, and the final decade of her life was hard to watch…Toward the end, she gave up hope. ‘This is just the way it goes’, she told me. She died at the age of 92…but the more I have thought about it, the more I have come to believe that the person she truly was had been dead many years at that point.
Sinclair’s mother didn’t have an easy time either:
It was a quick death, thankfully, caused by a buildup of liquid in her remaining lung. We had just been laughing together about the eulogy I’d written on the trip from the United States to Australia, and then suddenly she was writhing on the bed, sucking for air that couldn’t satisfy her body’s demand for oxygen, staring at us with desperation in her eyes.
I leaned in and whispered into her ear that she was the best mom I could have wished for. Within a few minutes, her neurons were dying, erasing not just the memory of my final words to her but all of her memories. I know some people die peacefully. But that’s not what happened to my mother. In those moments she was transformed from the person who had raised me into a twitching, choking mass of cells, all fighting over the last residues of energy being created at the atomic level of her being.
All I could think was “No one ever tells you what it is like to die. Why doesn’t anyone tell you?
It would be facile to say “and that’s what made him become an anti-aging researcher”. He was already an anti-aging researcher at that point. And more important, everyone has this experience. If seeing your loved ones fade into shells of their former selves and then die painfully reliably turned you into an anti-aging researcher, who would be left to do anything else?
So his first argument is something like “maybe the thing where we’re all forced to watch helplessly as the people we love the most all die painfully is bad, and we should figure out some solution”. It’s a pretty compelling argument, one which has inspired generations of alchemists, mystics, and spiritual seekers.
[…]
But his second argument is: we put a lot of time and money into researching cures for cancer, heart disease, stroke, Alzheimers’, et cetera. Progress in these areas is bought dearly: all the low-hanging fruit has been picked, and what’s remaining is a grab bag of different complicated things – lung cancer is different from colon cancer is different from bone cancer.
The easiest way to cure cancer, Sinclair says, is to cure aging. Cancer risk per year in your 20s is only 1% what it is in your 80s. Keep everyone’s cells as healthy as they are in a 20-year-old, and you’ll cut cancer 99%, which is so close to a cure it hardly seems worth haggling over the remainder. As a bonus, you’ll get similar reductions in heart disease, stroke, Alzheimers, et cetera.
But also […] Sinclair thinks curing aging is easier than curing cancer. For one thing, aging might be just one thing, whereas cancer has lots of different types that need different strategies. For another, total cancer research spending approaches the hundreds of billions of dollars, whereas total anti-aging spending is maybe 0.1% of that. There’s a lot more low-hanging fruit!
And also, even if we succeed at curing cancer, it will barely matter on a population level. If we came up with a 100% perfect cure for cancer, average US life expectancy would increase two years – from 80 to 82. Add in a 100% perfect cure for heart disease, and you get 83. People mostly get these diseases when they are old, and old people are always going to die of something. Cure aging, and the whole concept of life expectancy goes out the window.
There are a lot of people who get angry about curing aging, because maybe God didn’t mean for us to be immortal, or maybe immortal billionaires will hog all the resources, or [insert lots of other things here]. One unambitious – but still potentially true – counterargument to this is that a world where we conquered aging, then euthanized everyone when they hit 80, would still be infinitely better than the current world where we age to 80 the normal way.
But once you’ve accepted this argument, there are some additional reasons to think conquering death would be good.
First, the environmental sustainability objection isn’t really that strong. If 50% of people stopped dying (maybe some people refuse the treatment, or can’t afford it), that would increase the US population by a little over a million people a year over the counterfactual where people die at the normal rate. That’s close to the annual number of immigrants. If you’re not worried about the sustainability of immigration, you probably shouldn’t worry about the sustainability of ending death.
You can make a similar argument for the world at large: life expectancy is a really minimal driver of population growth. The world’s longest-lived large country, Japan, currently has negative population growth; the world’s shortest-lived large country, Somalia, has one of the highest population growth rates in the world. If 25% of the world population took immortality serum (I’m decreasing this from the 50% for USA because I’m not even sure 50% of the world’s population has access to basic antibiotics), that would increase world population by 15 million per year over the counterfactual. It would take 60 years for there to even be an extra billion people, and in 60 years a lot of projections suggest world population will be stable or declining anyway. By the time we really have to worry about this we’ll either be dead or colonizing space.
Second, life expectancy at age 10 (ie excluding infant mortality) went up from about 45 in medieval Europe to about 85 in modern Europe. What bad things happened because of this? Modern Europe is currently in crisis because it has too few people and has to import immigrants from elsewhere in the world. And the increase didn’t cause some kind of stagnation where older people prevented society from ever changing. It didn’t cause some sort of perma-dictatorship where old people refuse to let go of their resources and the young toil for scraps. It corresponded to the period of the most rapid social and economic progress anywhere in history.
Would Europe be better off if the government killed every European the day they turned 45? If not, it seems like the experiment with extending life expectancy from 45 to 85 went pretty well. Why not try the experiment of extending life expectancy from 85 to 125, and see if that goes well too?
And finally, what’s the worst that could happen? An overly literal friend has a habit of always answering that question with “everyone in the world dies horribly”. But in this case, that’s what happens if we don’t do it. Seems like we have nowhere to go but up!
I think all of this is spot-on – but in particular, I think that last point is worth giving a long hard look in the context of the whole AI risk debate. The main argument for avoiding ASI is that it might lead to all of us dying – but the thing is, “all of us dying” is the outcome that will happen if we don’t get ASI. It’s not just a strong possibility; it’s what will definitely, 100% happen to every single one of us if we never reach the Singularity. (True, we could use biotechnology alone to extend our lifespans by quite a bit without turning to ASI, as Alexander describes; but as other commentators like Arvin Ash and Holger von Jouanne-Diedrich point out, even if we figured out how to reverse aging and cure every disease, that’d still only give the average person a few centuries before they died in an accident or a natural disaster or something like that. For true immortality (i.e. immortality lasting as long as the universe itself lasts), we’d need ASI and nanotechnology and the whole rest of the package, or something equivalent.) What that means, then, is that our choice of whether or not to pursue the Singularity isn’t actually a choice between “definitely stay alive” (if we decide not to risk it) versus “maybe die” (if we do) – it’s a choice between “stay alive for a few more years but then definitely die” (if we don’t go for it) versus “maybe die or maybe unlock immortality” (if we do).
Of course, if the AI safety skeptics are actually right and our odds of successfully navigating the Singularity are particularly low – like, lower than 50% even in the best-case scenario where we’ve taken every possible precaution and implemented every conceivable safeguard – then the idea that we should still go for it anyway becomes a much harder pill to swallow. As Bryan Caplan illustrates with a thought experiment:
Suppose you receive the following option.
You flip a fair coin.
If the coin is Heads, you acquire healthy immortality.
If the coin is Tails, you instantly die.
The expected value of this option seems infinite: .5*infinity + 0 is still infinity, no? Even if you apply diminishing marginal utility to life itself, it’s hard to imagine that the rest of your natural life outweighs a 50% shot of eternity… especially if you remember that many of your actual years are unlikely to be healthy.
Nevertheless, I suspect that almost no one would take this deal. Even I shudder at the possibility. So what gives?
Caplan is right that most people would probably balk at the idea of flipping the coin, just because the immediacy of the threat of death would overwhelm all other considerations. What’s interesting, though, as David Henderson points out in the replies, is that if you asked them whether they’d do it when they were in their 90s, near the very end of their lifespan, the offer would suddenly become a lot more appealing, and most people probably would accept it then. With so little time left for them to potentially lose, the downside of flipping the coin would suddenly seem like much less of an issue. I also suspect that for the same reason, if you told people that their natural lifespan would only be, say, two days, and they’d be offered the coin flip when they were one day old, most of them would probably take the offer in that scenario as well. Even though it would mean flipping the coin just halfway through their natural lifespans, they’d still want to do it just because there would be so little time left for them even if they declined the offer. The deciding factor, in other words, wouldn’t necessarily be how far they were through their lifespans; it would just be how close they were to death in absolute terms.
But here’s the thing: The situation we’re in right now, where most of us have maybe 30-40 years left in our natural lifespans (if we’re lucky), is essentially that same scenario. In absolute terms, 30-40 years is very close to death. The fact that we naturally only live for 80 or so years makes us feel like 30-40 years is quite a long time (in much the same way that a mayfly probably feels like 24 hours is a long time) – but considering things in the context of a potential post-Singularity world, 30-40 years is barely a blip. Our true potential lifespans in a post-Singularity world would be measured in eons, not decades – so from the perspective of a trillion-year-old post-Singularity transhuman looking back on our present day, the notion that a 40-year-old might decline the coin flip just so they could be assured of living for another 30-40 years would seem as absurd as a 90-year-old declining it on their deathbed just so they could be assured of living for another day or two, or a mayfly declining the offer just so it could be assured of living for a few more hours.
Ultimately, then, if our goal is really to avoid death, we have no better option than to take the gamble, even if the odds aren’t especially favorable. No doubt, the downside risk is unspeakably massive; in the worst-case scenario where we completely blow it and inadvertently wipe out the entire species, eight billion people who would otherwise have lived for another 40 years on average will instead be killed instantly. Having said that, though, the fact that each of those people would only have been expected to live for another 40 years or so would mean that even this total extinction event would “only” equate to the destruction of about 320 billion years of human life – whereas if we actually managed to carry off the Singularity successfully, it would mean vastly more than 320 billion years of human life would be gained, since each of us who would otherwise have died in those 40 or so years would now be able to live for another trillion trillion years if we wanted to. In other words, having the opportunity to pursue the Singularity, but choosing never to do so because of the risks, would mean the loss of trillions upon trillions of potential life-years – orders of magnitude more than the mere billions that would be lost in the instant-doom scenario. Accordingly, what the pure utility calculus would suggest is that we really should be trying our hardest to reach the Singularity, even despite the existential risks.
(Of course, you might object to this logic on the grounds that it doesn’t fully acknowledge all that would actually be lost if humanity were completely wiped out. By only counting life-years destroyed, it’s not accounting for all the potential life-years that would never be realized if we destroyed ourselves, because in doing so we would also be destroying the possibility for any future generations. But as I discussed in my metaethics post, the argument for ascribing moral value to purely hypothetical people who never actually come into existence isn’t one that can ultimately hold up, simply because it’s not possible to do moral harm to people who never come into existence in the first place. In order for something to be harmful, it has to actually be harmful to somebody. So any system of ethics that counts it as a moral harm to violate some potential person’s hypothetical preference to be brought into existence is ultimately untenable, and leads to failure modes like the Repugnant Conclusion and so on. You might want to insist that nevertheless, there would still be some abstract sense in which the universe would just innately be worse off without any living beings in it. But again, in such a universe, there wouldn’t be anyone around for anything to actually be worse for – it would all just be uncaring rocks and gas clouds – so the concept would cease to have any meaning (except inasmuch as it would be thwarting our present-day desires for our species not to go extinct). I won’t rehash the whole argument here; but like I said, you can see the metaethics post for a fuller explanation if you’re not entirely convinced.)
So okay then, if reaching the Singularity really should be our driving goal, then does this mean just trying to get there as fast as we can, even at the expense of safety? You might be tempted to argue, based on the above logic, that if we could reach the Singularity even just one year earlier by forgoing some safety precautions, it would mean that the 60 million people who would otherwise have died in that year would instead be able to live for trillions of years – a gain that would so vastly outweigh the potential downside risk of losing 320 billion life-years in an AI-induced extinction event that it would be worth rushing the process even if it meant accepting a significantly higher risk level. In fact, as it happens, this was the attitude that I myself held up until very recently. But I changed my mind after seeing a counterargument from commenter LostaraYil21, who pointed out that the massive gain in life-years we could potentially attain in the best-case scenario is in fact all the more reason why we shouldn’t rush the process, but should instead spend however long it takes to make sure that our odds are as high as they can possibly be. After all, if (let’s say) we rush things and thereby cause there to be a 50-50 chance of either absolute extinction or everyone gaining an extra trillion years in life expectancy, that would equate to an expected value of (0.5)*(8 billion trillion life-years added)-(0.5)*(320 billion life-years lost), for a net total of ~3.9999 billion trillion expected life-years added – whereas if we take an extra year to improve safety by even just one percentage point, making it a 51-49 chance of survival, that would make it an expected value of (0.51)*(7.94 billion trillion life-years added)-(0.49)*(320 billion life-years lost), for a total of ~4.05 billion trillion expected life-years added – an unfathomably massive difference. So even though 60 million people would die during that one extra year of development and would never get to enjoy all those extra trillions of life-years, their loss would still be outweighed by the increased chance we’d be giving ourselves that we wouldn’t all be forced to miss out on all those extra life-years. The upside of ensuring that we reached the Singularity safely would just be so massive that it would be worth it even if it meant that millions of people would have to miss the boat. Now, naturally, at some point all the safety measures would have to reach a point of diminishing returns, where it would no longer be possible to come up with any further safety improvements within a time frame that would make them worthwhile. So at some point we’d just have to pull the trigger and go for it. The point here, though, is just that we’d need to make damn sure we were taking every possible measure to maximize our expected value in doing so. In other words, there are two goals that we need to simultaneously bear in mind when approaching this problem: (1) we must not waste even a single moment in trying to reach the Singularity, lest immeasurable quantities of human life be lost; and (2) the most crucial part of successfully accomplishing that goal is to make sure we aren’t destroyed in the process – so we must do everything within our power to ensure that the transition is a safe one. That is to say, there’s no time to waste – but time spent maximizing safety is not wasted. It might seem like these two goals are in tension, but they’re both absolutely critical. It’s like if, say, there were some extreme emergency scenario in which a massive global pandemic was rapidly killing off the population, and the only cure was some exotic mineral from the surface of the moon, and we only had enough material to build one rocketship to go up and retrieve it. In this scenario, we’d be under immense pressure to launch the ship as quickly as we possibly could, so no one would have to needlessly die due to our dawdling – but also, we’d only have one shot at getting it right; if the ship malfunctioned and blew up, we wouldn’t get a second chance. So while it would be morally imperative not to delay the launch for even a moment longer than necessary, it would be even more imperative to make sure the ship was safe and wouldn’t blow up, even if that meant losing some additional lives in the short term because we took slightly longer to fully foolproof it. It wouldn’t be easy to insist on doing our full due diligence while our loved ones were dropping like flies all around us – but it would be the right call in the end. It would be crucial to do the job quickly, but it would be even more crucial to do it right.
Now, having said all that, there are a couple of possibilities – extremely remote ones, in my view, but possibilities nonetheless – that could make this whole apparent dilemma a moot point. For starters, the entire argument for not wasting any time has been predicated on the assumption that death is irreversible and can never be undone; but if it turned out that it was somehow possible for a sufficiently advanced ASI to bring people back to life – not just to make perfect recreations of past people, but to fully restore their actual bodies and brains, atom for atom, even after they’d long since turned to dust – then obviously that would change things quite a bit. Needless to say, this would require the ASI to be impossibly powerful; I’m imagining that it would literally have to be something like Laplace’s Demon, capable of somehow knowing the position and momentum of every particle in the universe, and then tracing them backward through time to determine the precise atomic makeup of everyone who’d ever died, then bringing each person’s atoms back together again to perfectly reconstruct them in the present. And this is something I have a hard time imagining that even the most advanced ASI would be able to pull off, for a whole host of reasons (not least of which being that calculating the path of every particle in the universe would presumably require as much computing power as existed in the universe itself). But if a future ASI could actually figure it out – and I’d hesitate to put anything past an entity with an IQ millions of times greater than my own, even if it involved circumventing the laws of physics somehow – then that would negate everything I’ve been saying about the importance of reaching the Singularity as quickly as safely possible. There would no longer be any urgency to push ahead in order to save people from being lost forever, because that risk would no longer exist; anyone who died before the Singularity could just be brought back later. In that scenario, the only important thing would simply be reaching the Singularity as safely as possible regardless of how long it took. And that would mean that instead of pushing steadily ahead, we’d instead want to go as slowly as possible – not just moderately slowly, but absurdly slowly – just so we could be sure we were doing everything as safely as we possibly could. There would no longer be any time pressure, so we’d be able to take our time and make sure we were getting everything absolutely perfectly right. Obviously, this would be the best-case scenario of all – so if it could be somehow shown that such an outcome would actually be possible, even in theory, I’d consider it the best news imaginable. But like I said, I’m not counting on it. I think that whether we like it or not, we’re going to have to save people from death before they die if we’re going to save them at all – and that means moving more quickly than the bare minimum.
…Unless, that is, there’s no chance at all that we’ll actually be able to achieve a positive Singularity, even under the best possible conditions. That’s the second big counterargument that could invalidate everything I’ve been saying here: If the people who are most pessimistic about ASI are actually right, and there’s literally zero chance we’ll be able to create ASI without it backfiring on us, then it should go without saying that we shouldn’t pursue it at all, and should completely stop AI development before it reaches the point of no return. To be sure, the case they’ve made for the reality of AI risk is an extremely strong one; they’ve certainly convinced me, at least, that it’s the biggest potential threat our species has ever faced. That being said, though, I’m still not convinced that it’s absolutely inevitable that continued AI development will necessarily lead to doom with near-total certainty. My overall impression (and again, I really want to stress how much I’m not an expert here, but just giving my general sense of things from the outside view) is that it is in fact possible to build an advanced AI that doesn’t decide to wipe us all out – and that we may even have a very good chance of doing so. It strikes me as entirely plausible, for instance, that once we’ve progressed far enough in our AI development, it’ll start to become apparent that there’s no feasible way to have a narrow AI make the leap to full AGI without it forming something like what we’d call “common sense” in the process; to repeat Piper’s line from earlier, “maybe alignment will turn out to be part and parcel of other problems we simply must solve to build powerful systems at all.” Or maybe it’ll turn out that we don’t actually have to figure out the alignment problem for non-human ASIs in the first place, because our first ASIs will come from emulations of scanned-and-uploaded human brains rather than being coded entirely from scratch. I could imagine a scenario in which, say, we continue to develop AI normally over these next few years, right up until the point where we haven’t quite achieved full AGI but have progressed far enough that AIs are able to figure out how to build technology to perfectly scan human brains and make digital replicas of them – and then at that point, we have those digital human brains bootstrap themselves into full ASIs, and we achieve superintelligence without ever having to run the risk of non-human ASI misalignment. (As Paul Christiano has suggested, this might not even need to involve recreating digital brains from the bottom up by mapping out all the individual neurons; instead, we might just give an advanced AI a bunch of neuroimaging data from a specific human brain, along with instructions to create some kind of digital model from scratch that produces those same outputs, and it’ll turn out that the simplest model it can create that meets the criteria is, in fact, an emulation of that very human brain – so the AI will have reverse-engineered the brain from the top down without ever even understanding it at the base level.) Or maybe neither of those scenarios will happen, and we actually will have to figure out the alignment problem, but we’ll be able to do so successfully by tackling it from some creative angle that turns it from an overwhelming all-or-nothing challenge to one that’s much more manageable and forgiving. Russell’s principles for inverse reinforcement learning, for instance (as summarized here by Wikipedia), seem like a genuinely promising example of the kind of approach that could actually work:
Russell begins by asserting that the standard model of AI research, in which the primary definition of success is getting better and better at achieving rigid human-specified goals, is dangerously misguided. Such goals may not reflect what human designers intend, such as by failing to take into account any human values not included in the goals. If an AI developed according to the standard model were to become superintelligent, it would likely not fully reflect human values and could be catastrophic to humanity.
[…]
Russell [instead] proposes an approach to developing provably beneficial machines that focus on deference to humans. Unlike in the standard model of AI, where the objective is rigid and certain, this approach would have the AI’s true objective remain uncertain, with the AI only approaching certainty about it as it gains more information about humans and the world. This uncertainty would, ideally, prevent catastrophic misunderstandings of human preferences and encourage cooperation and communication with humans.
[…]
Russell lists three principles to guide the development of beneficial machines. He emphasizes that these principles are not meant to be explicitly coded into the machines; rather, they are intended for human developers. The principles are as follows:
The machine’s only objective is to maximize the realization of human preferences.
The machine is initially uncertain about what those preferences are.
The ultimate source of information about human preferences is human behavior.
The “preferences” Russell refers to “are all-encompassing; they cover everything you might care about, arbitrarily far into the future.” Similarly, “behavior” includes any choice between options, and the uncertainty is such that some probability, which may be quite small, must be assigned to every logically possible human preference.
Russell explores inverse reinforcement learning, in which a machine infers a reward function from observed behavior, as a possible basis for a mechanism for learning human preferences.
If it’s important to control AI, and easy solutions like “put it in a box” aren’t going to work, what do you do?
[Reading Russell’s response to this question will be] exciting for people who read Bostrom but haven’t been paying attention since. Bostrom ends by saying we need people to start working on the control problem, and explaining why this will be very hard. Russell is reporting all of the good work his lab at UC Berkeley has been doing on the control problem in the interim – and arguing that their approach, Cooperative Inverse Reinforcement Learning, succeeds at doing some of the very hard things. If you haven’t spent long nights fretting over whether this problem was possible, it’s hard to convey how encouraging and inspiring it is to see people gradually chip away at it. Just believe me when I say you may want to be really grateful for the existence of Stuart Russell and people like him.
Previous stabs at this problem foundered on inevitable problems of interpretation, scope, or altered preferences. In Yudkowsky and Bostrom’s classic “paperclip maximizer” scenario, a human orders an AI to make paperclips. If the AI becomes powerful enough, it does whatever is necessary to make as many paperclips as possible – bulldozing virgin forests to create new paperclip mines, maliciously misinterpreting “paperclip” to mean uselessly tiny paperclips so it can make more of them, even attacking people who try to change its programming or deactivate it (since deactivating it would cause fewer paperclips to exist). You can try adding epicycles in, like “make as many paperclips as possible, unless it kills someone, and also don’t prevent me from turning you off”, but a big chunk of Bostrom’s [book Superintelligence] was just example after example of why that wouldn’t work.
Russell argues you can shift the AI’s goal from “follow your master’s commands” to “use your master’s commands as evidence to try to figure out what they actually want, a mysterious true goal which you can only ever estimate with some probability”. Or as he puts it:
The problem comes from confusing two distinct things: reward signals and actual rewards. In the standard approach to reinforcement learning, these are one and the same. That seems to be a mistake. Instead, they should be treated separately…reward signals provide information about the accumulation of actual reward, which is the thing to be maximized.
So suppose I wanted an AI to make paperclips for me, and I tell it “Make paperclips!” The AI already has some basic contextual knowledge about the world that it can use to figure out what I mean, and my utterance “Make paperclips!” further narrows down its guess about what I want. If it’s not sure – if most of its probability mass is on “convert this metal rod here to paperclips” but a little bit is on “take over the entire world and convert it to paperclips”, it will ask me rather than proceed, worried that if it makes the wrong choice it will actually be moving further away from its goal (satisfying my mysterious mind-state) rather than towards it.
Or: suppose the AI starts trying to convert my dog into paperclips. I shout “No, wait, not like that!” and lunge to turn it off. The AI interprets my desperate attempt to deactivate it as further evidence about its hidden goal – apparently its current course of action is moving away from my preference rather than towards it. It doesn’t know exactly which of its actions is decreasing its utility function or why, but it knows that continuing to act must be decreasing its utility somehow – I’ve given it evidence of that. So it stays still, happy to be turned off, knowing that being turned off is serving its goal (to achieve my goals, whatever they are) better than staying on.
This also solves the wireheading problem. Suppose you have a reinforcement learner whose reward is you saying “Thank you, you successfully completed that task”. A sufficiently weak robot may have no better way of getting reward than actually performing the task for you; a stronger one will threaten you at gunpoint until you say that sentence a million times, which will provide it with much more reward much faster than taking out your trash or whatever. Russell’s shift in priorities ensures that won’t work. You can still reinforce the robot by saying “Thank you” – that will give it evidence that it succeeded at its real goal of fulfilling your mysterious preference – but the words are only a signpost to the deeper reality; making you say “thank you” again and again will no longer count as success.
Of course, Alexander adds that this approach still has a ways to go before it can be fully perfected and implemented:
All of this sounds almost trivial written out like this, but number one, everything is trivial after someone thinks about it, and number two, there turns out to be a lot of controversial math involved in making it work out (all of which I skipped over). There are also some big remaining implementation hurdles. For example, the section above describes a Bayesian process – start with a prior on what the human wants, then update. But how do you generate the prior? How complicated do you want to make things? Russell walks us through an example where a robot gets great information that a human values paperclips at 80 cents – but the real preference was valuing them at 80 cents on weekends and 12 cents on weekdays. If the robot didn’t consider that a possibility, it would never be able to get there by updating. But if it did consider every single possibility, it would never be able to learn anything beyond “this particular human values paperclips at 80 cents on 12:08 AM on January 14th when she’s standing in her bedroom.” Russell says that there is “no working example” of AIs that can solve this kind of problem, but “the general idea is encompassed within current thinking about machine learning”, which sounds half-meaningless and half-reassuring.
So it’s certainly not a foregone conclusion that this approach of inverse reinforcement learning will ultimately be successful in the long run. Still, it does seem promising enough that the idea of just throwing up our hands and declaring that we’ll never be able to resolve the alignment problem feels like premature defeatism. Russell’s approach – or something like it – actually seems like it could (and I daresay probably would) work if implemented; or if nothing else, it seems like it’s on the right track. And in fact, a number of theorists – including even Bostrom, who’s known for being wary of advanced AI in general – have offered creative speculations about how such an approach could hypothetically work. Here’s one of Bostrom’s ideas, for instance:
Suppose we write down a description of a set of values on a piece of paper. We fold the paper and put it in a sealed envelope. We then create an agent with human-level general intelligence, and give it the following final goal: “Maximize the realization of the values described in the envelope.” What will this agent do?
The agent does not initially know what is written in the envelope. But it can form hypotheses, and it can assign those hypotheses probabilities based on their priors and any available empirical data. For instance, the agent might have encountered other examples of human-authored texts, or it might have observed some general patterns of human behavior. This would enable it to make guesses. One does not need a degree in psychology to predict that the note is more likely to describe a value such as “minimize injustice and unnecessary suffering” or “maximize returns to shareholders” than a value such as “cover all lakes with plastic shopping bags.”
When the agent makes a decision, it seeks to take actions that would be effective at realizing the values it believes are most likely to be described in the letter. Importantly, the agent would see a high instrumental value in learning more about what the letter says. The reason is that for almost any final value that might be described in the letter, that value is more likely to be realized if the agent finds out what it is, since the agent will then pursue that value more effectively. The agent would also discover the convergent instrumental reasons described [earlier] — goal system integrity, cognitive enhancement, resource acquisition, and so forth. Yet, assuming that the agent assigns a sufficiently high probability to the values described in the letter involving human welfare, it would not pursue these instrumental values by immediately turning the planet into computronium and thereby exterminating the human species, because doing so would risk permanently destroying its ability to realize its final value.
We can liken this kind of agent to a barge attached to several tugboats that pull in different directions. Each tugboat corresponds to a hypothesis about the agent’s final value. The engine power of each tugboat corresponds to the associated hypothesis’s probability, and thus changes as new evidence comes in, producing adjustments in the barge’s direction of motion. The resultant force should move the barge along a trajectory that facilitates learning about the (implicit) final value while avoiding the shoals of irreversible destruction; and later, when the open sea of more definite knowledge of the final value is reached, the one tugboat that still exerts significant force will pull the barge toward the realization of the discovered value along the straightest or most propitious route.
And potential solutions like this aren’t the only ones being proposed, either. There’s a whole array of other strategies that are currently being explored, and new ideas in the space are emerging every day. No one knows which of these strategies (if any) will prove to be successful, or if it’ll turn out that none of them are even necessary in the first place because misaligned AI never ends up becoming a real threat after all. This is all unexplored territory. And while that does mean there’s a very real chance that we could be taken by surprise by some unforeseen AI-induced cataclysm, it also means we could just as easily be taken by surprise by how well things go and how effectively we’re able to address problems as they arise. It might very well turn out that the parts of AI development we don’t yet fully understand will actually end up working out in our favor.
Again, this isn’t something that we can just take for granted. If it turns out that something like inverse reinforcement learning is what ultimately allows us to achieve a successful Singularity, it’ll only be because AI researchers actually did the hard work of developing and implementing it. There’s no question that it’ll take a whole lot of effort and a whole lot of competence to make sure we get things absolutely right. But I do think we can get things right. It’s not guaranteed – not by a long shot – but it is possible.
As far as what our exact odds are in numerical terms – again, nobody can say for sure. For what it’s worth, a recent survey of experts on AI risk found that the median estimate of AI doom was about 10% (versus a 90% chance of survival), as Alexander explains:
The new paper [by] Carlier, Clarke, and Schuett (not currently public, sorry, but you can read the summary here) […] instead of surveying all AI experts, […] surveys people who work in “AI safety and governance”, ie people who are already concerned with AI being potentially dangerous, and who have dedicated their careers to addressing this. As such, they were more concerned on average than the people in previous surveys, and gave a median ~10% chance of AI-related catastrophe (~5% in the next 50 years, rising to ~25% if we don’t make a directed effort to prevent it; means were a bit higher than medians). Individual experts’ probability estimates ranged from 0.1% to 100% (this is how you know you’re doing good futurology).
Alexander concludes that it’s noteworthy that “even people working in the field of aligning AIs mostly assign ‘low’ probability (~10%) that unaligned AI will result in human extinction” – and I agree; this is certainly a lot more encouraging than if the percentages were reversed. Still, you might reasonably argue that a 10% risk of total human extinction is still horrifyingly high. If you were about to board an airplane but then you found out there was a 10% chance it would crash, you would not board that plane. Personally, though, I don’t think this is actually the right analogy for our situation as a species – because like I said before, without ASI we’re all going to die anyway. To me, our current situation is more like sitting on a long conveyer belt called “mortality” that’s slowly moving toward a giant industrial shredding machine called “death;” and we don’t know what will happen to us if we jump off the conveyer belt – maybe there’s a 10% chance that it’ll turn out to be surrounded by lava or something, and jumping off will mean dying instantly instead of dying when we reach the end of the conveyer belt – but one thing we do know is that if we stay put instead of jumping off, it’s 100% certain that we’ll die. In that kind of situation, I’d consider jumping off the conveyer belt to be a risk worth taking, even with a 10% chance that we wouldn’t survive the attempt. And in fact, even if the odds were reversed and there was only a 10% chance of survival – or a 1% chance, for that matter – I’d still consider it a risk worth taking, simply because the alternative would be guaranteed death – slightly delayed death, sure, but guaranteed death nonetheless. So like I said before, it’s not a question of whether we want to risk dying now or die in 30-40 years; it’s a question of whether we want to die now (whether that’s right now or in 30-40 years – both are approximately “now”) or die in a trillion years (or however long we’d want to live in a post-Singularity world).
I realize this will be a pretty controversial way of looking at things. Even just writing it all out here, it feels like (if you’ll excuse one more analogy) sitting in a car that’s pointed toward a ramp at the edge of a massive canyon, and yelling “Floor it.” But the truth is, the side of the canyon we’re on right now isn’t safe; the specter of death is rushing toward us, and it will consume all of us if we stay put. The only hope any of us have of surviving is to make it to make it to the other side of the canyon. So as scary as it might be, and as real as the possibility of failure undoubtedly is, I see no better option than to just knuckle down, do everything within our power to make sure our car is safe and won’t fail on us, and then grit our teeth and hit the gas. The only thing worse than building the machine that kills us all is failing to build the machine that saves us all.
V.
In recent years, the two names that have become most associated with AI risk are Bostrom and Yudkowsky. Both of them have made extremely compelling arguments about the seriousness of AI risk and the possibility that it could lead to our total extinction. But along the route to becoming famous for these arguments, they’ve also both made similarly compelling arguments noting that if we could successfully use technology to escape our own mortality – to make it safely to the other side of the canyon, or to safely jump off the conveyer belt, or whichever analogy you prefer – it would be the single most important thing we could do as a species. Twenty years ago, for instance, Bostrom published his “Fable of the Dragon-Tyrant,” which he concluded thusly:
Searching for a cure for aging [and “natural” death] is not just a nice thing that we should perhaps one day get around to. It is an urgent, screaming moral imperative. The sooner we start a focused research program, the sooner we will get results. It matters if we get the cure in 25 years rather than in 24 years: a population greater than that of Canada would die as a result. In this matter, time equals life, at a rate of approximately 70 lives per minute. With the meter ticking at such a furious rate, we should stop faffing about.
And a few years earlier, Yudkowsky delivered an even more impassioned mission statement to the same effect:
I have had it. I have had it with crack houses, dictatorships, torture chambers, disease, old age, spinal paralysis, and world hunger. I have had it with a planetary death rate of 150,000 sentient [human] beings per day. I have had it with this planet. I have had it with mortality. None of this is necessary. The time has come to stop turning away from the mugging on the corner, the beggar on the street. It is no longer necessary to look nervously away, repeating the mantra: “I can’t solve all the problems of the world.” We can. We can end this.
And so I have lost, not my faith, but my suspension of disbelief. Strange as the Singularity may seem, there are times when it seems much more reasonable, far less arbitrary, than life as a human. There is a better way! Why rationalize this life? Why try to pretend that it makes sense? Why make it seem bright and happy? There is an alternative!
I’m not saying that there isn’t fun in this life. There is. But any amount of sorrow is unacceptable. The time has come to stop hypnotizing ourselves into believing that pain and unhappiness are desirable! Maybe perfection isn’t attainable, even on the other side of Singularity, but that doesn’t mean that the faults and flaws are okay. The time has come to stop pretending it doesn’t hurt!
Our fellow humans are screaming in pain, our planet will probably be scorched to a cinder or converted into goo, we don’t know what the hell is going on, and the Singularity will solve these problems. I declare reaching the Singularity as fast as possible to be the Interim Meaning of Life, the temporary definition of Good, and the foundation until further notice of my ethical system.
Of course, once again, it really can’t be stressed enough that the most critical part of “reaching the Singularity as fast as possible” – as Bostrom and Yudkowsky themselves will be the first to tell you – is ensuring that we don’t destroy ourselves before we can get there. If our development of AI capabilities is outpacing our development of AI safety, that isn’t helping us reach the Singularity more quickly; all it’s doing is helping us reach an early doom more quickly. And in the subsequent years since writing the above, as AI development has accelerated, Bostrom and Yudkowsky have shifted their emphasis to this latter point and become more adamant than anyone that we not just recklessly plow forward on AI capabilities until we’re sure we’ve got a legitimately solid handle on the safety side of things (which, in their view, we currently don’t). Granted, we’ll never be able to reduce the risk to absolutely zero; at the end of the day, there’s simply no way to guarantee that we’ll be able to cover all our bases if the technology we’re aiming to create is more intelligent than any of us. And even despite the fact that the risk level will have to be greater than zero, it’ll still be worth accepting that risk – even if it ultimately remains relatively high after all’s said and done – simply because the potential payoff will be so massive. Nevertheless, doing everything we can to minimize the level of risk that we do have to accept has to be priority number one in our broader mission to reach the Singularity as quickly as we can, precisely because the stakes are so high. As for whether we actually will be able to minimize the risk… that’s currently an open question. One thing’s for sure, though: These next few years leading up to the answer will be the biggest moment of truth we’ve ever faced as a species. As Yudkowsky puts it:
I would seriously argue that we are heading for the critical point of all human history. Modifying or improving the human brain, or building strong AI, is huge enough on its own. When you consider the intelligence explosion effect, the next few decades could determine the future of intelligent life.
So this is probably the single most important issue in the world. Right now, almost no one is paying serious attention. And the marginal impact of additional efforts could be huge.
And Bostrom agrees, summing up the whole issue in his TED talk before concluding with the line: “I can imagine that if things turn out okay, that people a million years from now look back at this century, and it might well be that they say that the one thing we did that really mattered was to get this thing right.”
I think this is spot on. For all intents and purposes, reaching the Singularity will either mean an end to all of our troubles, or an end to us. If it’s really true, then, that this critical turning point will actually happen within our lifetimes – maybe even within these next couple of decades – we should be devoting as much time and energy to it now as we possibly can. As Urban writes:
No matter what you’re pulling for, this is probably something we should all be thinking about and talking about and putting our effort into more than we are right now.
It reminds me of Game of Thrones, where people keep being like, “We’re so busy fighting each other but the real thing we should all be focusing on is what’s coming from north of the wall.” We’re standing on our balance beam [poised between extinction and immortality], squabbling about every possible issue on the beam and stressing out about all of these problems on the beam when there’s a good chance we’re about to get knocked off the beam.
And when that happens, none of these beam problems matter anymore. Depending on which side we’re knocked off onto, the problems will either all be easily solved or we won’t have problems anymore because dead people don’t have problems.
That’s why people who understand superintelligent AI call it the last invention we’ll ever make—the last challenge we’ll ever face.
So let’s talk about it.
What exactly would it mean to give this issue as much attention as it deserves? Well, aside from just trying to make it a bigger part of our collective conversation, as Urban suggests, another thing that would certainly help would be to immediately start pouring as many of our resources (financial and non-financial) into the relevant research areas as possible. AI research has already begun attracting a ton of private-sector funding in recent years as its potential has become increasingly apparent – which is a good start. But I’ll also just reiterate what I said in my last post, which is that the public sector should be throwing its entire weight behind such research as well – and not just in AI, but in all the other fields I’ve been discussing here (nanotechnology, brain-machine interfacing, etc. – including, of course, safety research for all of the above). As I wrote before, there’s a very real sense in which we should consider government’s most important role right now to simply be serving as a tool for empowering scientists and engineers and programmers – ensuring that the background social conditions of stability and prosperity are maintained to a sufficient degree to allow them to pursue their research without impediment, and helping advance them in their quest in every way possible (with funding, education, etc.). As things currently stand, the number of people who are actually out there in the world doing real important scientific research (particularly the kind of research that would be directly applicable to the Singularity) is, once you crunch the numbers, startlingly low (see Josiah Zayner’s post on the subject here). And among the working researchers who do exist, competition for funding and support is often incredibly fierce; researchers are frequently forced to spend an inordinate amount of their time jumping through hoops just to secure some limited resources for their work, rather than actually doing the work itself. In an ideal world, though, we would recognize the harm of impeding progress in this way, and would make it our highest priority to do just the opposite; any person who wanted to get a science or technology degree and pursue important research for a living would essentially be given a blank check to do so – think “Manhattan Project on steroids.” To quote Yudkowsky again:
Probably a lot of researchers on paths to the Singularity are spending valuable time writing grant proposals, or doing things that could be done by lab assistants. It would be a fine thing if there were a Singularity Support Foundation to ensure that these people weren’t distracted. There is probably one researcher alive today – Hofstadter, Drexler, Lenat, Moravec, Goertzel, Chalmers, Quate, someone just graduating college, or even me – who is the person who gets to the Singularity. Every hour that person is delayed is another hour to the Singularity. Every hour, six thousand people die. Perhaps we should be doing something about this person’s spending a fourth of [their] time and energy writing grant proposals.
No doubt, this kind of all-out research support would require a lot of spending – considerably more than what we’re devoting to it now – and it might even require issuing considerably more government debt. But if we had our priorities straight, this wouldn’t be a problem, because we’d recognize that in a post-Singularity world, with nanotechnology and advanced AI and everything else, whatever government debt we’d accrued up to that point would simply no longer be an issue, one way or another. Either our technology will have made us so fabulously wealthy that we’ll have no trouble repaying the debt (or we won’t even have any need for money at all, since we’ll be living in a post-scarcity techno-utopia), or else we ourselves will no longer exist. In either case, the immediate financial cost of throwing all our weight behind these research efforts isn’t the thing we should be worried about today.
Now, having said all that, are there other economic considerations that we should be worried about in the short term? We’ve been talking all about what might happen once we actually reach the finish line and achieve ASI and everything else, but just to shift gears a bit, what about the transitional period between now and then? How will all of this technological upheaval affect the economy more broadly, especially regarding things like employment? Sure, the researchers working in Singularity-relevant fields might get all the support and funding they need, but if AIs are about to start taking over more and more human tasks going forward, where will that leave the rest of us who aren’t employed in technological research? Are AIs just going to steal all of the jobs and create mass unemployment? Are they just going to make their owners rich while leaving everyone else without any means of supporting themselves? This might seem like a comparatively trivial thing to talk about after having just spent so much time talking about the threat of total extinction and so on; but more and more people are raising it as a real concern nowadays, so I think it’s worth briefly addressing before we wrap things up here. I should mention that this is another one of those topics I’ve already covered in an earlier post, so I’ll basically just be copying here what I wrote in that post (and if you’ve already read that one, you can just skim over this part); but just to reiterate, the short answer is no, technology probably won’t create mass unemployment (at least not until we’ve fully reached the Singularity and no longer have any need for jobs in the first place).
It’s not hard to understand why technological unemployment might seem like a major threat, of course. AIs really have been improving exponentially, and have been overtaking human capabilities in more and more areas recently. If things keep going the way they are, it won’t be long before they’ve surpassed humans across the board, and are capable of doing every job better than humans can. So at that point, isn’t it obvious that humans won’t have any place left in the job market?
Well, if such a scenario actually did take place, let’s think about how it would have to happen. Let’s imagine that a dozen or so mega-conglomerates develop machines so advanced that they’re able to perform literally any task better and more cheaply than the best humans. These firms’ owners (let’s say each firm is owned by just one person) would have no reason at this point not to lay off their entire workforce and replace those workers with machines. And likewise, nobody inside or outside these firms would have any reason to buy anything from anyone other than them, since the fully-automated firms’ products would be better and cheaper than anyone else’s. But this would also mean that no other businesses would be able to compete with these firms, so they’d all go out of business, and everyone except the firms’ owners would be out of a job. And without any stream of income, that would mean that nobody would be able to buy the firms’ products, aside from the dozen or so rich owners of the firms themselves. So ultimately, we’d have a situation in which there were a dozen or so rich individuals using machines to create whatever products their hearts desired, which they then exchanged among themselves – and then the entire rest of the population would just be sitting around doing nothing, unable to engage in any kind of transactions at all.
But wait a minute – that can’t be right, can it? If that were the situation, then everyone outside the fully-automated firms could just as easily pretend that those firms didn’t exist at all, and could simply continue transacting with each other and conducting the same kind of normal economy that we have today, completely separate from anything the firms were doing. After all, the firms’ owners would already be completely ignoring them and not buying anything from them, so they’d already essentially be existing in their own separate bubble economy, with no money or products crossing the boundary in either direction. No one would be able to trade with the firms’ owners even if they wanted to (aside from the owners themselves); so the only way for regular people to obtain goods and services would be to produce them themselves and trade with each other, just as they’re currently doing. So does that mean that the ultimate effect of firms completely automating their workforce would be that nothing would change at all (aside from a dozen or so rich people breaking off into a whole separate second economy)? The story doesn’t quite seem to add up.
So what are we missing? Why wouldn’t the rich owners, with their technology allowing them to be more productive at everything than anyone else, simply secede into a state of absolute self-sufficiency and leave the rest of us behind? Well, when we put it that way, we can just as well ask the same question of people right now who are in the top percentile of capability and potential productivity. After all, there are people out there right now who are stronger and smarter and more capable in practically every way than practically everyone else (think NASA astronauts, for instance). So why do those people still engage in transactions with the rest of us regular people? The short answer is an economic concept called comparative advantage. The idea of comparative advantage is that even if a particular person is more efficient at everything than another person, the fact that they can only do one thing at a time means that it can still be worthwhile for both parties to trade with each other, since doing so would ultimately produce more overall output than each of them trying to do everything on their own. So for instance, let’s say we had a dozen people – six highly productive ones who were each capable of either assembling 20 televisions or giving 10 haircuts per hour, and six less productive ones who were each only capable of assembling 2 televisions or giving 4 haircuts per hour. The more productive group, seeing that they’re more efficient at producing both televisions and haircuts, might decide that they don’t need the second group, and so might decide to produce everything on their own, with three of them assembling televisions and three of them giving haircuts. Meanwhile, the less productive group, forced to fend for themselves, would split up their labor the same way – three of them assembling televisions, and three giving haircuts. Altogether, then, this would result in the first group producing 60 televisions and 30 haircuts per hour for themselves, while the second group produced 6 televisions and 12 haircuts per hour, for a total of 66 televisions and 42 haircuts overall. Another way that things might go, however, would be for both groups to realize that they could be even more productive if they each spent more of their time doing what they were best at (relatively speaking), and then traded with each other as needed. So let’s say one of the more efficient ones switched from giving haircuts to assembling televisions, and three of the less efficient ones switched from assembling televisions to giving haircuts. With this new division of labor, the first group would now be producing 80 televisions and 20 haircuts per hour, while the second group would be producing zero televisions but 24 haircuts per hour, for a total of 80 televisions and 44 haircuts overall. The first group could then sell 11 televisions to the second group in exchange for 11 haircuts, which would leave the first group with 69 televisions and 31 haircuts per hour (an improvement of 9 additional televisions and 1 additional haircut compared to before) and the second group with 11 televisions and 13 haircuts per hour (an improvement of 5 televisions and 1 additional haircut). Everyone would be made better off! That’s the magic of free exchange. And the exact same dynamic can be applied to our aforementioned scenario in which one group of people was extremely productive because they owned a fleet of hyper-efficient machines, and another group of people was less productive because they were just regular workers. Even if the machines were superior to the human workers in literally every way, it would still be worthwhile for their owners to trade with the regular workers – because after all, the mere fact that a machine can do anything doesn’t mean it can do everything. It can still only do one thing at a time; and accordingly, all that matters in the end is what its relative advantages are, not what its absolute advantages are. As Lori G. Kletzer puts it:
Even in a world where robots have absolute advantage in everything — meaning robots can do everything more efficiently than humans can — robots will be deployed where they have the greatest relative productivity advantage. Humans, meanwhile, will work where they have the smallest disadvantage. If robots can produce 10 times as many automobiles per day as a team of humans, but only twice as many houses, it makes sense to have the robots specialize and focus full-time where they’re relatively most efficient, in order to maximize output. Therefore, even though people are a bit worse than robots at building houses, that job still falls to humans.
In the trade model we end up insisting that there is always a comparative advantage. Even if (as is quite likely it true) the US is better at making absolutely everything than Eritrea is it is still to the benefit of both Eritrea and the US to trade between the two. For it allows both to concentrate on their comparative advantage.
When we switch this over to thinking about jobs and work I like to invert it. Not in meaning but in phrasing: if we all do what we’re least bad at and trade the resulting production then we’ll be better off overall. For example, I am not the best in the world at doing anything. I’m not even the best at being Tim Worstall, for I know there’s at least a couple of other people with the same name and it wouldn’t surprise me at all to find out that one or other of them is better at being Tim Worstall than I am. There are also people out there who are better at doing absolutely everything than I am. And yet the world still pays me a living as long as I do what I am least bad at and trade that for what others are least bad at.
The same will obviously be true when the robots are better than us at doing everything. It will still be true that we will be better off by doing whatever we are least bad at because that will be an addition to whatever it is that the robots are making. If what the robots make isn’t traded with us then obviously the economy will be much as it is now. We’ll be consuming what other humans make for us to consume in much the same manner we do now. If the robots do trade with us then we’re still made better off by working away at whatever it is that we do least badly. And the third possible outcome is that there is in fact some limit to human wants and desires and the robots make so much of everything that they manage to satiate us. At which point, well, who cares about a job as we’ve now, by definition because our desires are satiated, got everything we want? (I strongly suspect that there will still be shortages of course, the love of a good woman isn’t going to become in excess supply anytime soon I fear.)
The end state therefore cannot be something to fear. I agree that the transition could be a bit interesting (in that supposed Chinese sense of “interesting times”) but the actual destination of the robots being better than us at everything seems quite pleasant.
In short, then, as long as we’re willing and able to do work, work should be available to us; we won’t have to worry about robots making us all permanently unemployable. And what’s even better, as the robots become more and more productive, it will mean that we’ll be able to receive more and more from them in exchange for less and less labor on our part. Instead of having to do a week’s worth of labor just to be able to afford a new television or washing machine, it’ll eventually get to the point where we’re able to afford new televisions and washing machines with barely any effort at all – just like how we can now afford to buy food for a fraction of what it would have cost our ancestors in terms of labor expended. And ultimately, once we’ve gotten to the point where we’re nearly at the Singularity and the robots have gotten really efficient and productive – like, as efficient as it’s physically possible for them to get – the amount of labor we’ll have to expend in order to afford everything we could possibly want will basically be negligible. Once we have advanced AIs and nanofabricators and so on, the only “labor” we’ll have to perform at that point will just be dropping the occasional clump of dirt or garbage into the nanofabricators to be reassembled into sports cars or gourmet meals or cancer cures or whatever. As Worstall puts it, “jobs” as we currently understand them will no longer be considered necessary at all, because we’ll already have everything we could ever want. And when we look back on our current era, the notion that people might have ever been afraid of “robots taking all the jobs” will seem hopelessly confused.
Again though, all of this is assuming that we don’t destroy ourselves in the process of developing all these technologies – which, as the technologies grow more and more powerful, will become more and more of a legitimate threat with each passing year. We’ve already talked all about the existential risk we’ll be facing once we reach these technologies’ full potential – and naturally, that will be the biggest threat of all – but even before we get to that point, there will also be plenty of other serious dangers and complications along the way, aside from just the misplaced worry that AIs will take all our jobs. As Nathan J. Robinson writes, even just having technologies that are merely extremely powerful (as opposed to being totally all-powerful) will raise some major challenges in the immediate future:
The conceivable harms from AI are endless. If a computer can replicate the capacities of a human scientist, it will be easy for rogue actors to engineer viruses that could cause pandemics far worse than COVID. They could build bombs. They could execute massive cyberattacks. From deepfake porn to the empowerment of authoritarian governments to the possibility that badly-programmed AI will inflict some catastrophic new harm we haven’t even considered, the rapid advancement of these technologies is clearly hugely risky.
[…]
I don’t think anyone can say for certain how likely it is that AI will be used to, for example, engineer a virus that wipes out human civilization. Maybe it’s quite unlikely. But given the scale of the risk, I don’t want to settle for quite unlikely. We need the chance of that happening to be as close to zero as possible. [Likewise,] I’ve been on the record as a skeptic of the hypothesis that a rogue AI, sufficiently capable of improving its own intelligence, could turn on humanity and drive us to extinction. But you don’t need to think that scenario is especially likely to think that we should at least make sure that there’s always an “off switch” built in to intelligent machines. The costs of safety are so low when compared to the costs of the worst outcomes that it’s an absolute no-brainer.
Even if, like Robinson, you’re skeptical of the idea of a misaligned AI eventually going rogue and turning the world into paperclips, you have to admit that the possibility of ill-intentioned humans using AI for malicious purposes will still be a very real danger in its own right, simply because the possibility of ill-intentioned humans misusing new technology is always a danger. This won’t just be limited to AI, either; the more widespread technologies like bioengineering become, the easier it will become for (say) some ordinary run-of-the-mill extremist to create a bioweapon that wipes out all of humanity. And this danger will only be multiplied once we unlock the massive power of molecular nanotechnology; as we discussed earlier, if we somehow end up inventing self-replicating nanobots before we invent ASI, we won’t just have to worry about accidental gray goo scenarios, but intentionally triggered ones by malicious actors as well. In short, then, even if we completely exclude ASI from the equation, our odds of going extinct from the catastrophic misuse of technology in general are only going to increase in the near future. As Kurzweil writes:
We have a new existential threat today in the potential of a bioterrorist to engineer a new biological virus. We actually do have the knowledge to combat this problem (for example, new vaccine technologies and RNA interference which has been shown capable of destroying arbitrary biological viruses), but it will be a race. We will have similar issues with the feasibility of self-replicating nanotechnology [once it becomes potentially attainable]. Containing these perils while we harvest the promise is arguably the most important issue we face.
This is a point that has somehow become oddly neglected in modern debates over AI safety; these days, such debates usually just come down to disputes over how much risk (or lack thereof) we’d be creating for ourselves by inventing ASI, and don’t go any further than that. But as I’ve been stressing throughout this post, we can’t forget the dangers we’d be exposing ourselves to by not inventing ASI – because the way I see it, these are the greatest dangers of all. When it comes to nanotechnology in particular, I think there’s a good case to be made that the threat of uncontrolled nanotechnology without ASI would be even greater than the threat of ASI itself. And in fact, this was what originally made Yudkowsky himself want to push so hard for achieving ASI as quickly as possible, back when he was first writing on the subject:
Above all, I would really, really like the Singularity to arrive before nanotechnology, given the virtual certainty of deliberate misuse – misuse of a purely material (and thus, amoral) ultratechnology, one powerful enough to destroy the planet. We cannot just sit back and wait. To quote Michael Butler, “Waiting for the bus is a bad idea if you turn out to be the bus driver.”
[…]
Since [originally writing on this topic] in 1996, “nanotechnology” has gone public. I expect that everyone has now heard of the concept of attaining complete control over the molecular structure of matter. This would make it possible to create food from sewage, to heal broken spinal cords, to reverse old age, to make everyone healthy and wealthy, and to deliberately wipe out all life on the planet. Actually, the raw, destructive military uses would probably be a lot easier than the complex, creative uses. Anyone who’s ever read a history book gets one guess as to what happens next.
“Active shields” might suffice against accidental outbreaks of “grey goo”, but not against hardened military-grade nano, perfectly capable of using fusion weapons to break through active shields. And yet, despite this threat, we can’t even try to suppress nanotechnology; that simply increases the probability that the villains will get it first.
Mitchell Porter calls it “The race between superweapons and superintelligence.” Human civilization will continue to change until we either create superintelligence, or wipe ourselves out. Those are the two stable states, the two “attractors” in the system. It doesn’t matter how long it takes, or how many cycles of nanowar-and-regrowth occur before Transcendence or final extinction. If the system keeps changing, over a thousand years, or a million years, or a billion years, it will eventually wind up in one attractor or the other. But my best guess is that the issue will be settled now.
His mention of “active shields” there, by the way, is referring to a kind of global “immune system” that could be set up to protect against sudden outbreaks of all-consuming nanobot swarms – e.g. an invisible network of “police” nanobots distributed all around the world that would be able to intercept and neutralize malignant nanobots before they could do too much damage (in other words, a kind of “blue goo” to counteract the gray goo). This is one tool an ASI would be able to use to stop a nanobot attack from instantly wiping us all out. But as Yudkowsky mentions, it would just be one such tool designed to handle one specific threat; ASI would also have a whole array of tools for every conceivable threat and every conceivable problem, including ones that we can’t even imagine now.
And to be sure, our species will inevitably have to face major extinction-level threats in one form or another, whether we ever invent ASI or not. Whether it’s a deadly virus or a catastrophic war, or even something totally out of left field like (say) a swarm of all-consuming nanobots suddenly arriving without warning from some other star system where the Singularity has already been reached, we can imagine all kinds of ways in which humanity might be completely wiped out, unless we have some ultra-powerful way of protecting ourselves. And this might be the biggest reason of all to want to unlock ASI as soon as we safely can. Yes, there is a very real risk that it might destroy us; but there are also many other things that might destroy us, and the longer we go without ASI, the more of them there will be. Inventing ASI, even as risky as it would be in its own right, might very well be the best chance we’ll have at saving ourselves from extinction in overall terms. As commenter FosterKittenPurrs puts it:
I think that without ASI, there is a guarantee that something horrible will happen.
We may kill ourselves with nukes or other future weapons in a world war, maybe bio weapons or just accidental research escaping from a lab, nanobots, genetic engineering, climate change, through an asteroid, or maybe when we develop space infrastructure some drunk asteroid miner will fling that asteroid towards Earth etc.
With ASI, you only roll the dice once. You get it right, and it takes care of all this other crap for you. With everything else, you have to keep rolling the dice and hope you roll right every single time.
Needless to say, even having to roll the dice once on total annihilation feels like once too many. In an ideal world, we’d never have to make such a decision at all. But unfortunately, “never having to face the possibility of annihilation” doesn’t appear to be one of our options, and never will be – unless we can safely reach the Singularity. As things stand today, we aren’t just facing the possibility that all of us will die at some point – we’re facing a 100% guarantee of it; 60 million of us drop into the proverbial shredding machine every year, and the rest of us are steadily moving down the conveyer belt toward that same fate. Sure, if we keep reproducing, we can continually repopulate the conveyer belt with new people faster than the old ones drop off – and we’ve so far been able to keep the species going in that way. But there’s no guarantee that we’ll be able to keep that up forever – and even if there were, it wouldn’t actually matter in anything but the most abstract sense. “The human species,” after all, isn’t actually a moral end in itself; it’s not a conscious entity in its own right, with its own interests and its own inherent moral value (even though it’s often treated as such in discussions like this). Rather, “the human species” is just a shorthand term that we use to collectively refer to all the individual people who exist, and who do have innate moral value. Those individual people are what actually matter. And as of today, all of them – all of us – are doomed to die in just a few decades (or less) unless we can reach the Singularity first. That’s our only hope of ultimate survival. And yes, if we fail to do it right, there’s a very real risk that we’ll meet our doom a bit earlier than we otherwise would. But if we succeed, it’ll be nothing short of the greatest triumph ever accomplished; all those other threats and problems will simply disappear, and we really will be able to live happily ever after (or at least until the universe itself ends).
Of course, I can’t say for sure that any of this will happen exactly as I’ve been describing it. (That should hopefully go without saying.) Despite all the various confident-sounding predictions given by technology experts, nobody truly knows precisely how the future will play out. We might achieve full ASI by the end of this decade without ever encountering any significant problems with alignment at all, or it might turn out that there are major unanticipated obstacles that make it far more difficult than expected, so we don’t achieve ASI for another century or more; and neither outcome would completely shock me. I will say, though, what would shock me is if we don’t ever reach the Singularity (or go extinct) at any point in the future. Sooner or later, it seems inevitable to me that this is how the course of technology must eventually run, just based on everything we know about how machines work and what it’s physically possible for them to do. Whether or not we reach the critical turning point within our lifetimes is an open question – but whether or not it ever happens at all seems beyond doubt.
To wrap things up, then, I just want to address one final concern: Even if you do accept all of this, and you can in fact believe that our species as a whole really might be capable of reaching the Singularity, what does all this mean for you as an individual who may or may not personally live long enough to make it to 2035 or 2045 (or whenever the Singularity happens)? What should you do if you’re starting to approach old age, or are in poor health, or are simply worried about accidents or whatever, and you fear that you might be one of the billion or so people who won’t make it another decade or two (or if the Singularity takes much longer than that, the much larger chance that you’ll be one of those who doesn’t make it)? Well, obviously there aren’t really any great solutions here – if you get hit by a bus and die tomorrow, there’s not much that can be done about that. However, I will say that there might still be some small ray of hope to grab onto while you’re still alive today – specifically, cryonics. I’ve briefly discussed cryonics on here before (and I apologize again for repeating myself if you’ve already read that post), but just in case you missed it, cryonics is basically a way of having yourself preserved after you die (your body is vitrified and placed in super-cold liquid nitrogen) and then stored by a cryonics company for the next few decades (or centuries, or however long it takes) until technology has advanced enough for you to be revived and restored to full health. The idea is that while it might sound like pure sci-fi fantasy today, reviving a well-preserved body in this way would presumably be trivially easy in a post-Singularity world of ASI and nanotechnology and so on – so if your body can’t naturally survive until then, why not “put it on pause” until the Singularity does arrive? Obviously, there’s no guarantee that humanity actually will reach the Singularity safely – or even if it does, that the cryonics companies themselves will survive that long – so the whole venture is far from a sure thing. But still, the way I see it, even a small chance of surviving your own death is better than none at all. So if you can afford it (and it is expensive, but usually your life insurance company will pay the majority of the cost if you decide to sign up), it seems like a no-brainer to me. If you want to learn more (or if you’re still skeptical), Urban has an outstanding post here breaking down the whole process; I can’t recommend it enough. In fact, if you care about your continued survival as much as I do, I’d go so far as to say that it might be one of the most important things you ever read. (Clearer Thinking also has a great podcast episode on the subject here with Max Marty.) It might seem like a long shot from where we’re sitting here in the present day – in fact, all of this Singularity stuff might seem pretty unbelievable today, to put it mildly – but if it does all turn out to be for real, then as I said at the very beginning of this post, making it safely to the other side of the Singularity will be the most important thing that ever happens – not just for each of us as individuals, but for the entire universe as a whole. This is the thing that, if it goes right, will be the difference between oblivion and apotheosis for all sentient life everywhere. As far as I’m concerned, then, it’s worth taking very seriously, and doing whatever we have to do to make sure that it does go right. So cross your fingers – and hopefully I’ll see you on the other side. ∎